 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fine-Grain Error Map Prediction and Segmentation Quality Assessment Framework for Whole-Heart Segmentation
Paper and Code
Jul 29, 2019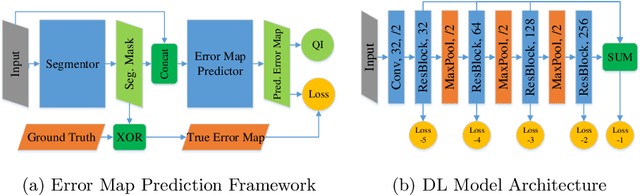
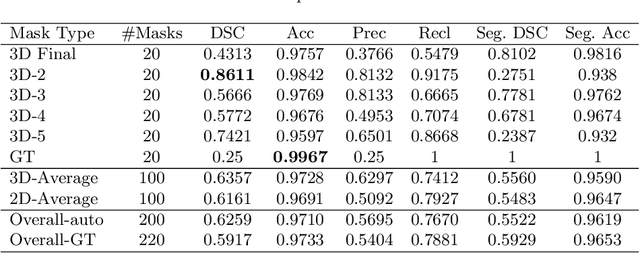
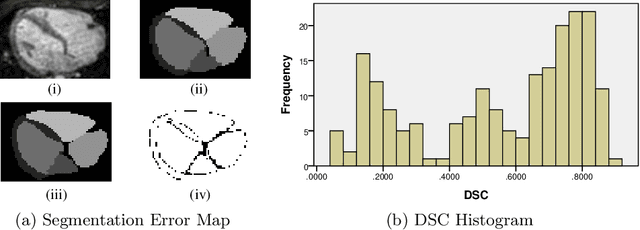
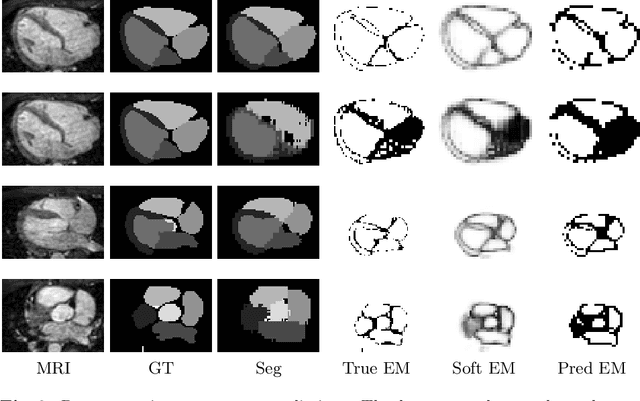
When introducing advanced image computing algorithms, e.g., whole-heart segmentation, into clinical practice, a common suspicion is how reliable the automatically computed results are. In fact, it is important to find out the failure cases and identify the misclassified pixels so that they can be excluded or corrected for the subsequent analysis or diagnosis. However, it is not a trivial problem to predict the errors in a segmentation mask when ground truth (usually annotated by experts) is absent. In this work, we attempt to address the pixel-wise error map prediction problem and the per-case mask quality assessment problem using a unified deep learning (DL) framework. Specifically, we first formalize an error map prediction problem, then we convert it to a segmentation problem and build a DL network to tackle it. We also derive a quality indicator (QI) from a predicted error map to measure the overall quality of a segmentation mask. To evaluate the proposed framework, we perform extensive experiments on a public whole-heart segmentation dataset, i.e., MICCAI 2017 MMWHS. By 5-fold cross validation, we obtain an overall Dice score of 0.626 for the error map prediction task, and observe a high Pearson correlation coefficient (PCC) of 0.972 between QI and the actual segmentation accuracy (Acc), as well as a low mean absolute error (MAE) of 0.0048 between them, which evidences the efficacy of our method in both error map prediction and quality assessment.