 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Federated Learning-based Industrial Health Prognostics for Heterogeneous Edge Devices using Matched Feature Extraction
Paper and Code
May 18, 2023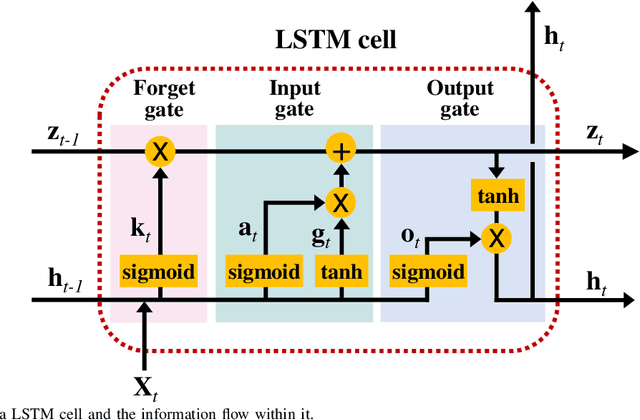
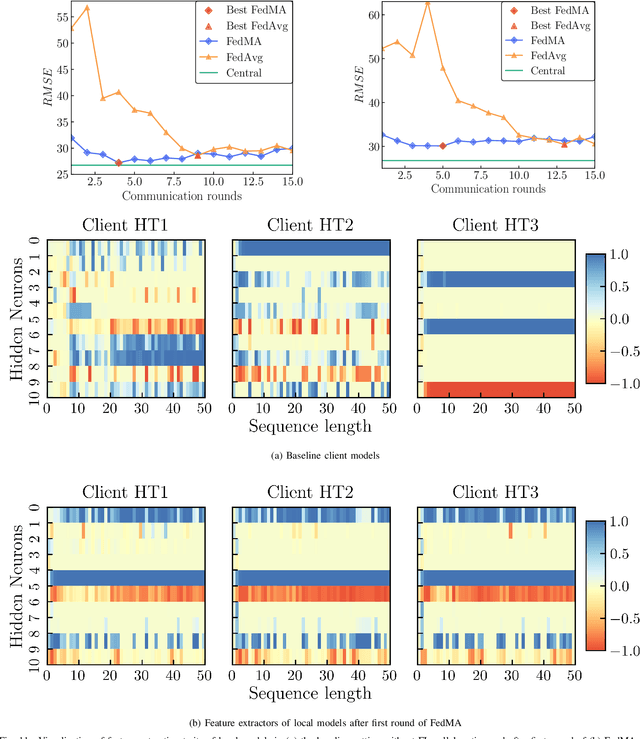
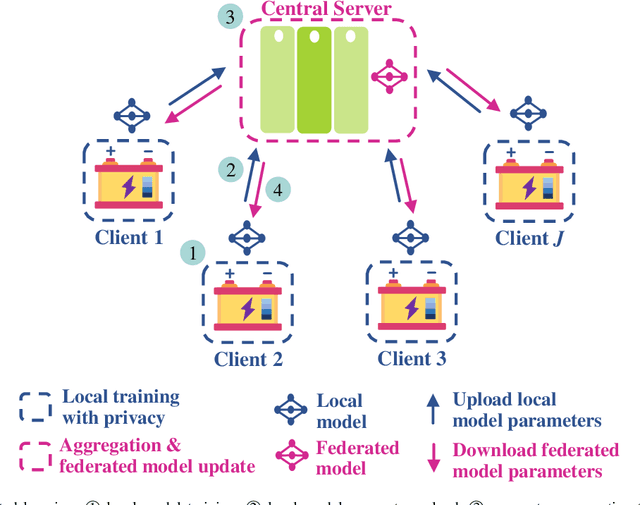
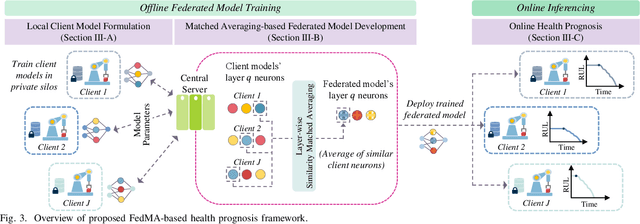
Data-driven industrial health prognostics require rich training data to develop accurate and reliable predictive models. However, stringent data privacy laws and the abundance of edge industrial data necessitate decentralized data utilization. Thus, the industrial health prognostics field is well suited to significantly benefit from federated learning (FL), a decentralized and privacy-preserving learning technique. However, FL-based health prognostics tasks have hardly been investigated due to the complexities of meaningfully aggregating model parameters trained from heterogeneous data to form a high performing federated model. Specifically, data heterogeneity among edge devices, stemming from dissimilar degradation mechanisms and unequal dataset sizes, poses a critical statistical challenge for developing accurate federated models. We propose a pioneering FL-based health prognostic model with a feature similarity-matched parameter aggregation algorithm to discriminatingly learn from heterogeneous edge data. The algorithm searches across the heterogeneous locally trained models and matches neurons with probabilistically similar feature extraction functions first, before selectively averaging them to form the federated model parameters. As the algorithm only averages similar neurons, as opposed to conventional naive averaging of coordinate-wise neurons, the distinct feature extractors of local models are carried over with less dilution to the resultant federated model. Using both cyclic degradation data of Li-ion batteries and non-cyclic data of turbofan engines, we demonstrate that the proposed method yields accuracy improvements as high as 44.5\% and 39.3\% for state-of-health estimation and remaining useful life estimation, respectively.