Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Faster $k$-means++ Algorithm
Paper and Code
Nov 28, 2022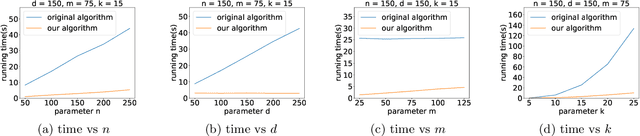

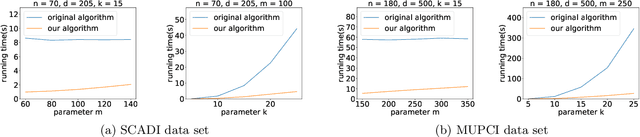
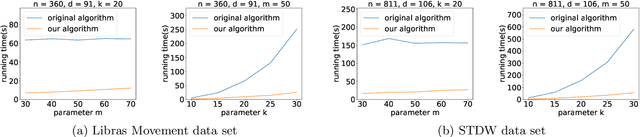
K-means++ is an important algorithm to choose initial cluster centers for the k-means clustering algorithm. In this work, we present a new algorithm that can solve the $k$-means++ problem with near optimal running time. Given $n$ data points in $\mathbb{R}^d$, the current state-of-the-art algorithm runs in $\widetilde{O}(k )$ iterations, and each iteration takes $\widetilde{O}(nd k)$ time. The overall running time is thus $\widetilde{O}(n d k^2)$. We propose a new algorithm \textsc{FastKmeans++} that only takes in $\widetilde{O}(nd + nk^2)$ time, in total.
View paper on