 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fast, Well-Founded Approximation to the Empirical Neural Tangent Kernel
Paper and Code
Jun 25, 2022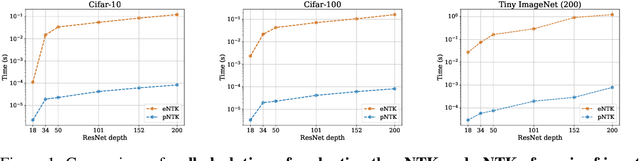
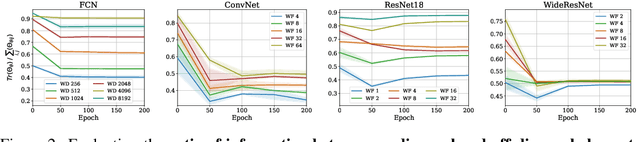
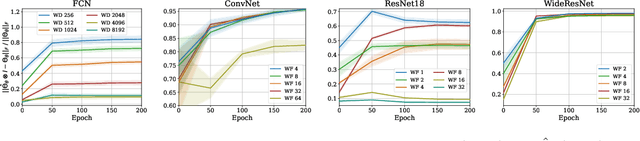
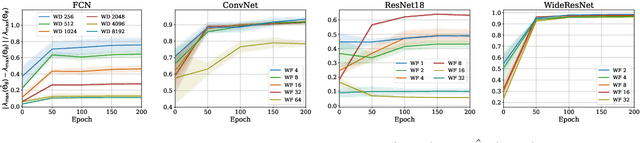
Empirical neural tangent kernels (eNTKs) can provide a good understanding of a given network's representation: they are often far less expensive to compute and applicable more broadly than infinite width NTKs. For networks with O output units (e.g. an O-class classifier), however, the eNTK on N inputs is of size $NO \times NO$, taking $O((NO)^2)$ memory and up to $O((NO)^3)$ computation. Most existing applications have therefore used one of a handful of approximations yielding $N \times N$ kernel matrices, saving orders of magnitude of computation, but with limited to no justification. We prove that one such approximation, which we call "sum of logits", converges to the true eNTK at initialization for any network with a wide final "readout" layer. Our experiments demonstrate the quality of this approximation for various uses across a range of settings.