 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA fast compression-based similarity measure with applications to content-based image retrieval
Paper and Code
Oct 02, 2012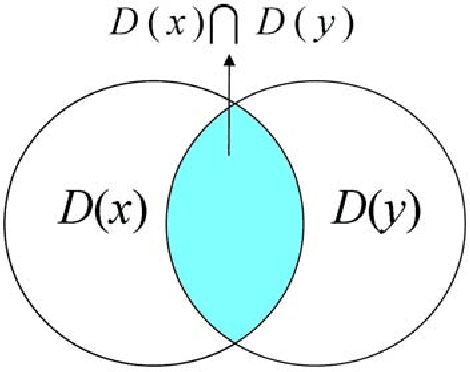
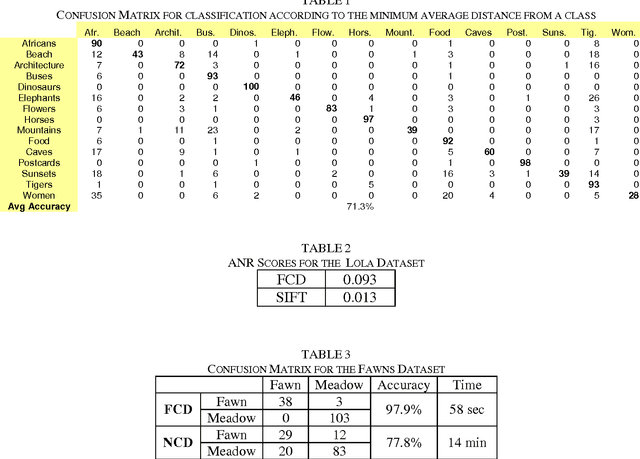
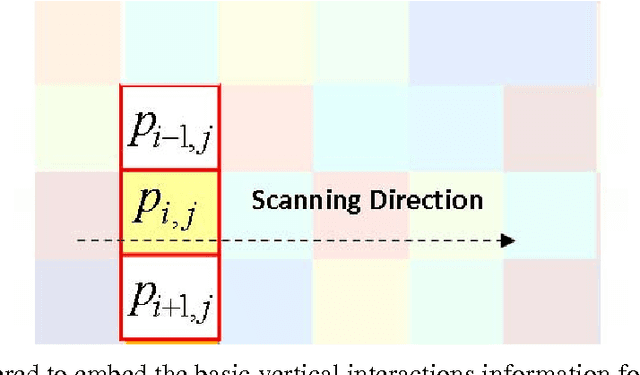
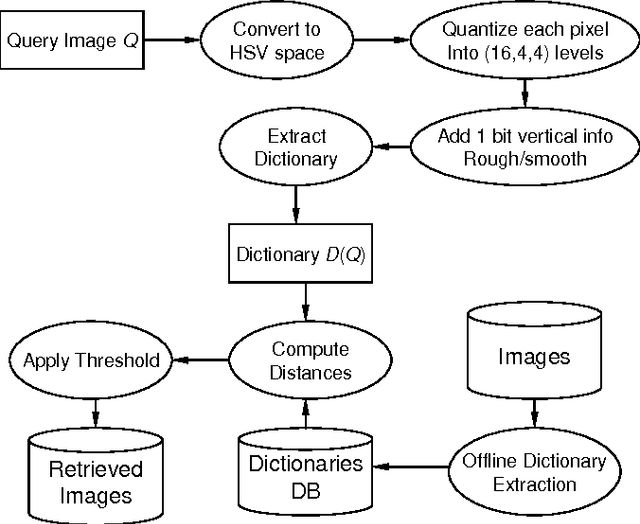
Compression-based similarity measures are effectively employed in applications on diverse data types with a basically parameter-free approach. Nevertheless, there are problems in applying these techniques to medium-to-large datasets which have been seldom addressed. This paper proposes a similarity measure based on compression with dictionaries, the Fast Compression Distance (FCD), which reduces the complexity of these methods, without degradations in performance. On its basis a content-based color image retrieval system is defined, which can be compared to state-of-the-art methods based on invariant color features. Through the FCD a better understanding of compression-based techniques is achieved, by performing experiments on datasets which are larger than the ones analyzed so far in literature.