 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Doubly Optimistic Strategy for Safe Linear Bandits
Paper and Code
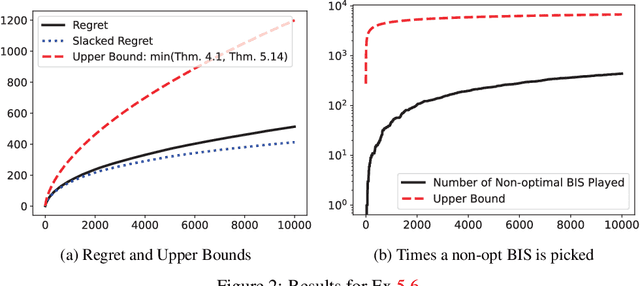
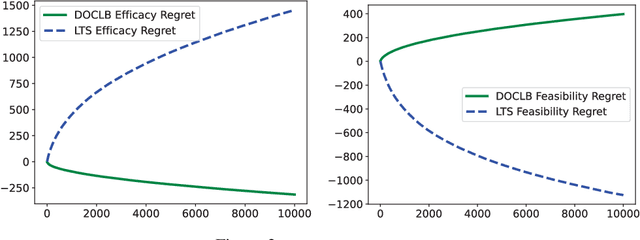
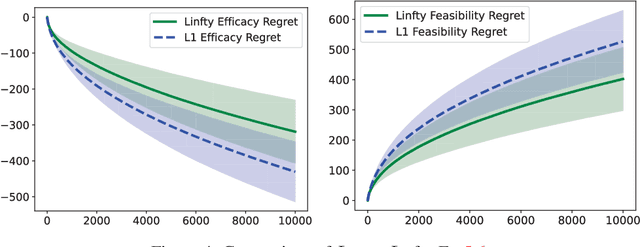
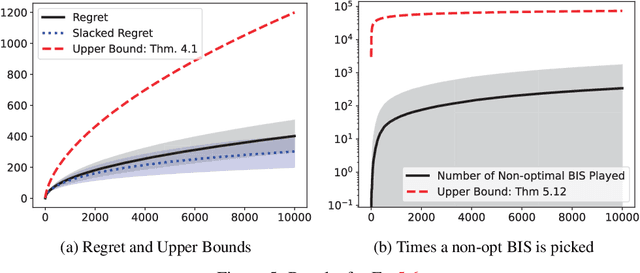
We propose a \underline{d}oubly \underline{o}ptimistic strategy for the \underline{s}afe-\underline{l}inear-\underline{b}andit problem, DOSLB. The safe linear bandit problem is to optimise an unknown linear reward whilst satisfying unknown round-wise safety constraints on actions, using stochastic bandit feedback of reward and safety-risks of actions. In contrast to prior work on aggregated resource constraints, our formulation explicitly demands control on roundwise safety risks. Unlike existing optimistic-pessimistic paradigms for safe bandits, DOSLB exercises supreme optimism, using optimistic estimates of reward and safety scores to select actions. Yet, and surprisingly, we show that DOSLB rarely takes risky actions, and obtains $\tilde{O}(d \sqrt{T})$ regret, where our notion of regret accounts for both inefficiency and lack of safety of actions. Specialising to polytopal domains, we first notably show that the $\sqrt{T}$-regret bound cannot be improved even with large gaps, and then identify a slackened notion of regret for which we show tight instance-dependent $O(\log^2 T)$ bounds. We further argue that in such domains, the number of times an overly risky action is played is also bounded as $O(\log^2T)$.