 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Distributed Deep Representation Learning Model for Big Image Data Classification
Paper and Code
Jul 02, 2016
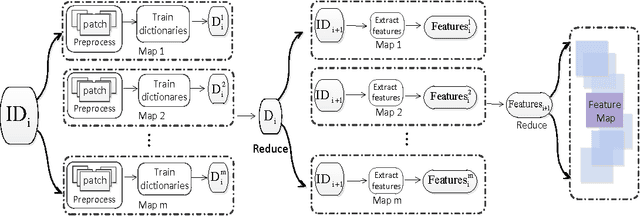
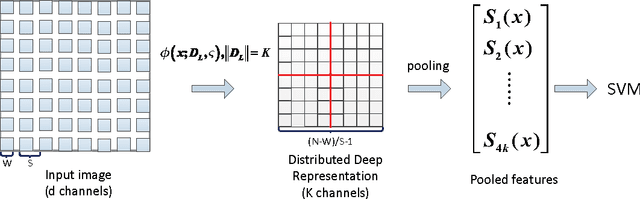

This paper describes an effective and efficient image classification framework nominated distributed deep representation learning model (DDRL). The aim is to strike the balance between the computational intensive deep learning approaches (tuned parameters) which are intended for distributed computing, and the approaches that focused on the designed parameters but often limited by sequential computing and cannot scale up. In the evaluation of our approach, it is shown that DDRL is able to achieve state-of-art classification accuracy efficiently on both medium and large datasets. The result implies that our approach is more efficient than the conventional deep learning approaches, and can be applied to big data that is too complex for parameter designing focused approaches. More specifically, DDRL contains two main components, i.e., feature extraction and selection. A hierarchical distributed deep representation learning algorithm is designed to extract image statistics and a nonlinear mapping algorithm is used to map the inherent statistics into abstract features. Both algorithms are carefully designed to avoid millions of parameters tuning. This leads to a more compact solution for image classification of big data. We note that the proposed approach is designed to be friendly with parallel computing. It is generic and easy to be deployed to different distributed computing resources. In the experiments, the largescale image datasets are classified with a DDRM implementation on Hadoop MapReduce, which shows high scalability and resilience.