 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deliberation-based Joint Acoustic and Text Decoder
Paper and Code
Mar 23, 2023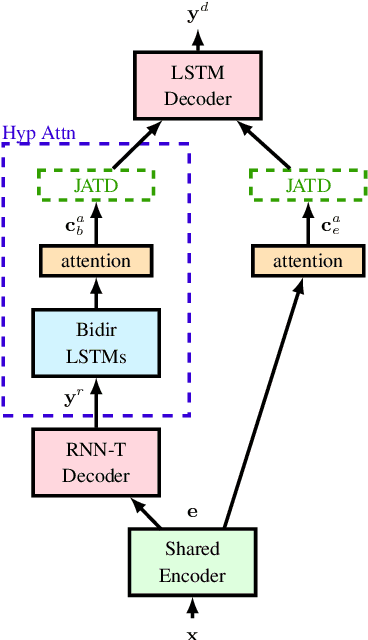
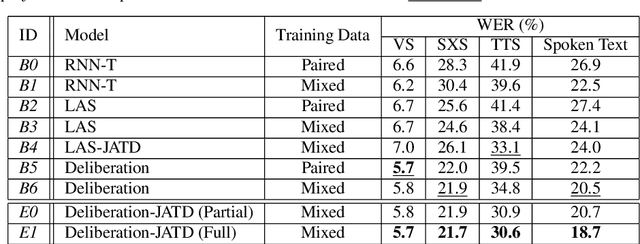
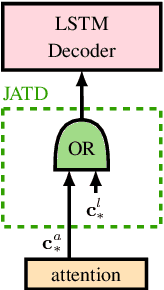
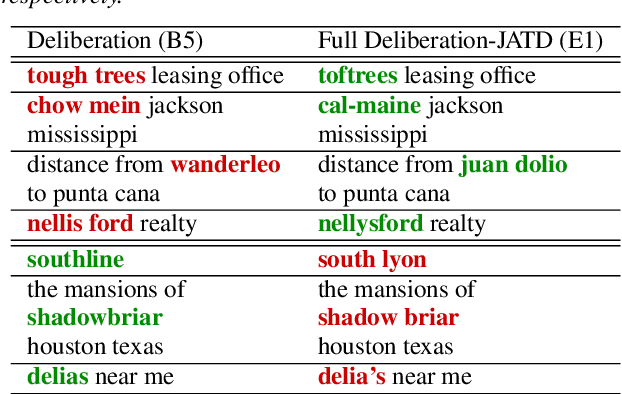
We propose a new two-pass E2E speech recognition model that improves ASR performance by training on a combination of paired data and unpaired text data. Previously, the joint acoustic and text decoder (JATD) has shown promising results through the use of text data during model training and the recently introduced deliberation architecture has reduced recognition errors by leveraging first-pass decoding results. Our method, dubbed Deliberation-JATD, combines the spelling correcting abilities of deliberation with JATD's use of unpaired text data to further improve performance. The proposed model produces substantial gains across multiple test sets, especially those focused on rare words, where it reduces word error rate (WER) by between 12% and 22.5% relative. This is done without increasing model size or requiring multi-stage training, making Deliberation-JATD an efficient candidate for on-device applications.