Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Siamese Network for Scene Detection in Broadcast Videos
Paper and Code
Oct 29, 2015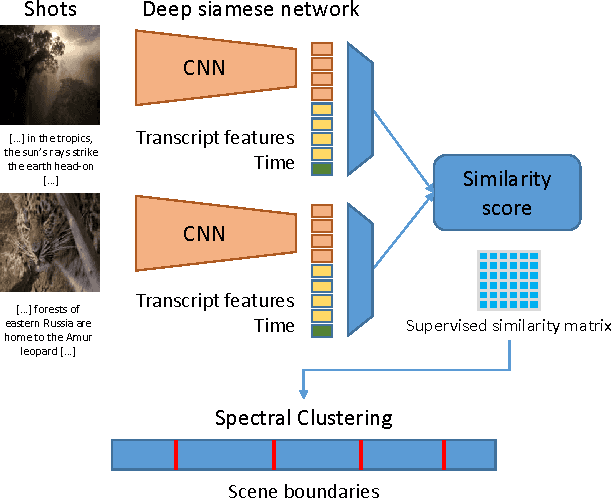
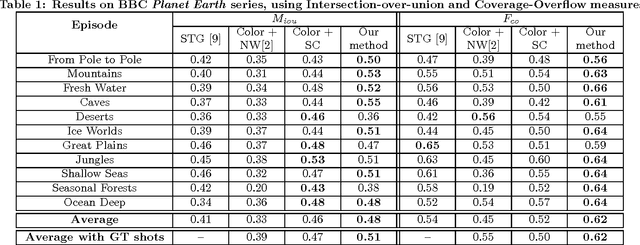
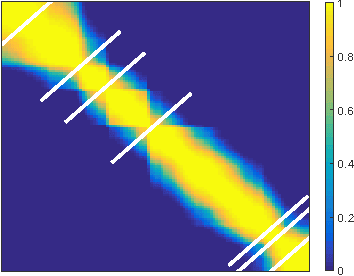
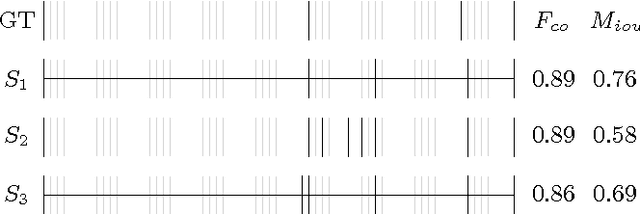
We present a model that automatically divides broadcast videos into coherent scenes by learning a distance measure between shots. Experiments are performed to demonstrate the effectiveness of our approach by comparing our algorithm against recent proposals for automatic scene segmentation. We also propose an improved performance measure that aims to reduce the gap between numerical evaluation and expected results, and propose and release a new benchmark dataset.
* ACM Multimedia 2015
View paper on