 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Decade's Battle on Dataset Bias: Are We There Yet?
Paper and Code


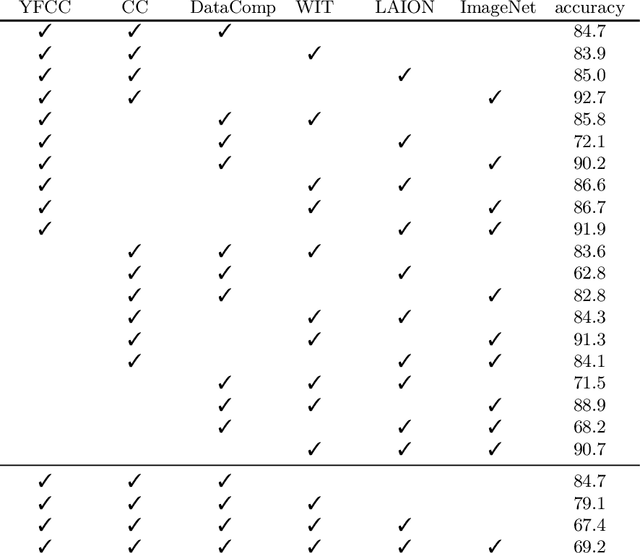
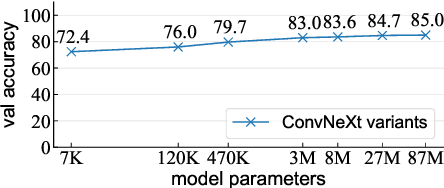
We revisit the "dataset classification" experiment suggested by Torralba and Efros a decade ago, in the new era with large-scale, diverse, and hopefully less biased datasets as well as more capable neural network architectures. Surprisingly, we observe that modern neural networks can achieve excellent accuracy in classifying which dataset an image is from: e.g., we report 84.7% accuracy on held-out validation data for the three-way classification problem consisting of the YFCC, CC, and DataComp datasets. Our further experiments show that such a dataset classifier could learn semantic features that are generalizable and transferable, which cannot be simply explained by memorization. We hope our discovery will inspire the community to rethink the issue involving dataset bias and model capabilities.