 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Curious Case of Searching for the Correlation between Training Data and Adversarial Robustness of Transformer Textual Models
Paper and Code
Feb 18, 2024


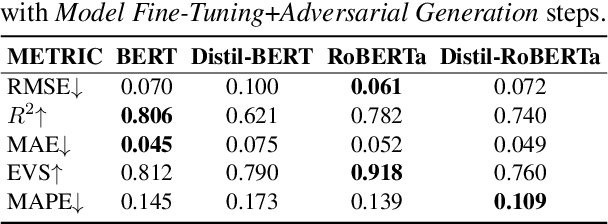
Existing works have shown that fine-tuned textual transformer models achieve state-of-the-art prediction performances but are also vulnerable to adversarial text perturbations. Traditional adversarial evaluation is often done \textit{only after} fine-tuning the models and ignoring the training data. In this paper, we want to prove that there is also a strong correlation between training data and model robustness. To this end, we extract 13 different features representing a wide range of input fine-tuning corpora properties and use them to predict the adversarial robustness of the fine-tuned models. Focusing mostly on encoder-only transformer models BERT and RoBERTa with additional results for BART, ELECTRA and GPT2, we provide diverse evidence to support our argument. First, empirical analyses show that (a) extracted features can be used with a lightweight classifier such as Random Forest to effectively predict the attack success rate and (b) features with the most influence on the model robustness have a clear correlation with the robustness. Second, our framework can be used as a fast and effective additional tool for robustness evaluation since it (a) saves 30x-193x runtime compared to the traditional technique, (b) is transferable across models, (c) can be used under adversarial training, and (d) robust to statistical randomness. Our code will be publicly available.