 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Corpus for English-Japanese Multimodal Neural Machine Translation with Comparable Sentences
Paper and Code
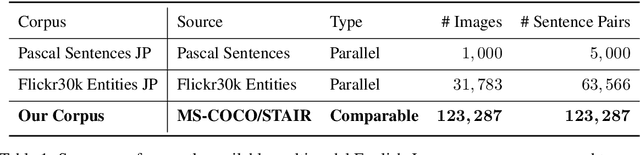

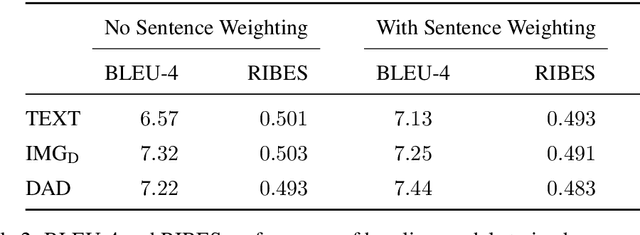
Multimodal neural machine translation (NMT) has become an increasingly important area of research over the years because additional modalities, such as image data, can provide more context to textual data. Furthermore, the viability of training multimodal NMT models without a large parallel corpus continues to be investigated due to low availability of parallel sentences with images, particularly for English-Japanese data. However, this void can be filled with comparable sentences that contain bilingual terms and parallel phrases, which are naturally created through media such as social network posts and e-commerce product descriptions. In this paper, we propose a new multimodal English-Japanese corpus with comparable sentences that are compiled from existing image captioning datasets. In addition, we supplement our comparable sentences with a smaller parallel corpus for validation and test purposes. To test the performance of this comparable sentence translation scenario, we train several baseline NMT models with our comparable corpus and evaluate their English-Japanese translation performance. Due to low translation scores in our baseline experiments, we believe that current multimodal NMT models are not designed to effectively utilize comparable sentence data. Despite this, we hope for our corpus to be used to further research into multimodal NMT with comparable sentences.