 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Convergent and Efficient Deep Q Network Algorithm
Paper and Code


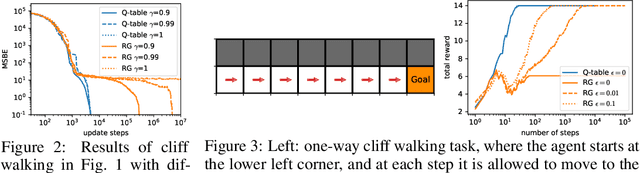

Despite the empirical success of the deep Q network (DQN) reinforcement learning algorithm and its variants, DQN is still not well understood and it does not guarantee convergence. In this work, we show that DQN can diverge and cease to operate in realistic settings. Although there exist gradient-based convergent methods, we show that they actually have inherent problems in learning behaviour and elucidate why they often fail in practice. To overcome these problems, we propose a convergent DQN algorithm (C-DQN) by carefully modifying DQN, and we show that the algorithm is convergent and can work with large discount factors (0.9998). It learns robustly in difficult settings and can learn several difficult games in the Atari 2600 benchmark where DQN fail, within a moderate computational budget. Our codes have been publicly released and can be used to reproduce our results.