 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Configurable Multilingual Model is All You Need to Recognize All Languages
Paper and Code
Jul 13, 2021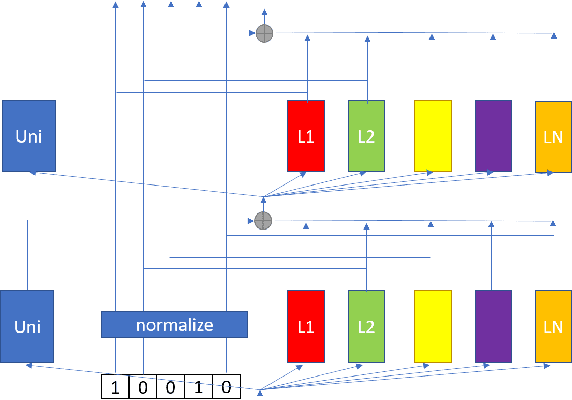
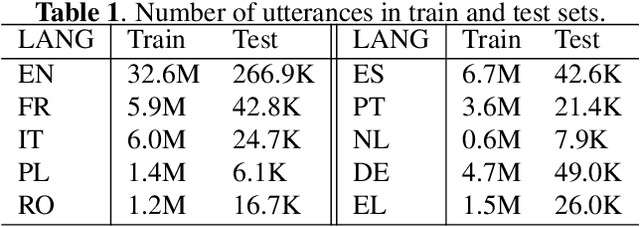
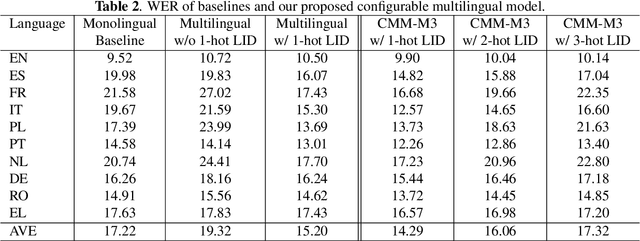
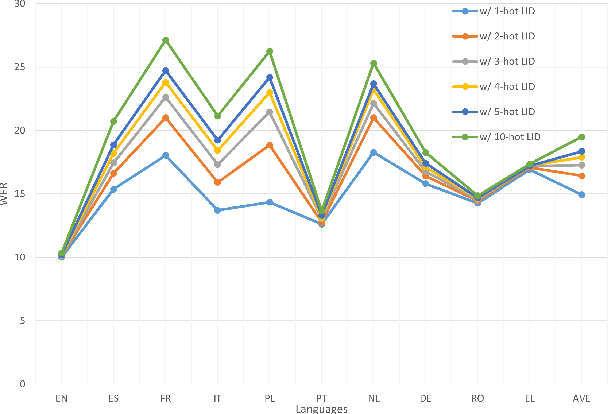
Multilingual automatic speech recognition (ASR) models have shown great promise in recent years because of the simplified model training and deployment process. Conventional methods either train a universal multilingual model without taking any language information or with a 1-hot language ID (LID) vector to guide the recognition of the target language. In practice, the user can be prompted to pre-select several languages he/she can speak. The multilingual model without LID cannot well utilize the language information set by the user while the multilingual model with LID can only handle one pre-selected language. In this paper, we propose a novel configurable multilingual model (CMM) which is trained only once but can be configured as different models based on users' choices by extracting language-specific modules together with a universal model from the trained CMM. Particularly, a single CMM can be deployed to any user scenario where the users can pre-select any combination of languages. Trained with 75K hours of transcribed anonymized Microsoft multilingual data and evaluated with 10-language test sets, the proposed CMM improves from the universal multilingual model by 26.0%, 16.9%, and 10.4% relative word error reduction when the user selects 1, 2, or 3 languages, respectively. CMM also performs significantly better on code-switching test sets.