 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Compression-Inspired Framework for Macro Discovery
Paper and Code
Feb 22, 2019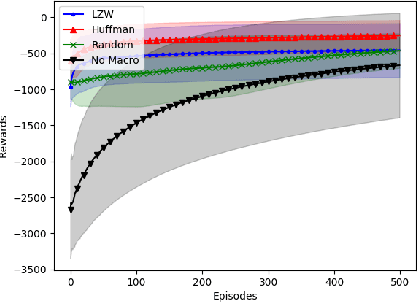
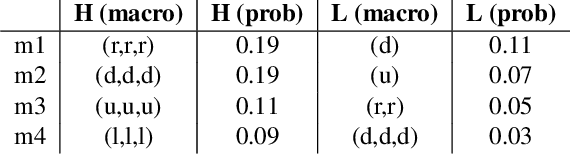
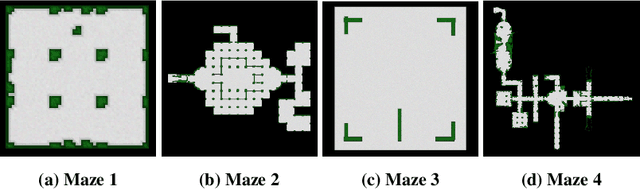
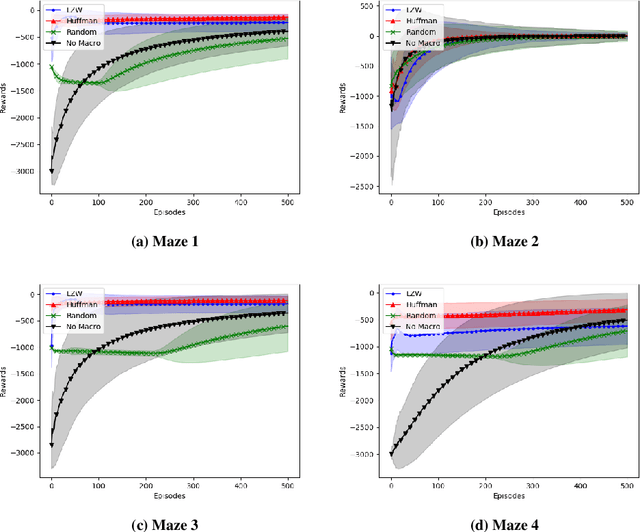
In this paper we consider the problem of how a reinforcement learning agent tasked with solving a set of related Markov decision processes can use knowledge acquired early in its lifetime to improve its ability to more rapidly solve novel, but related, tasks. One way of exploiting this experience is by identifying recurrent patterns in trajectories obtained from well-performing policies. We propose a three-step framework in which an agent 1) generates a set of candidate open-loop macros by compressing trajectories drawn from near-optimal policies; 2) evaluates the value of each macro; and 3) selects a maximally diverse subset of macros that spans the space of policies typically required for solving the set of related tasks. Our experiments show that extending the original primitive action-set of the agent with the identified macros allows it to more rapidly learn an optimal policy in unseen, but similar MDPs.