 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Compositional Approach to Language Modeling
Paper and Code
Apr 01, 2016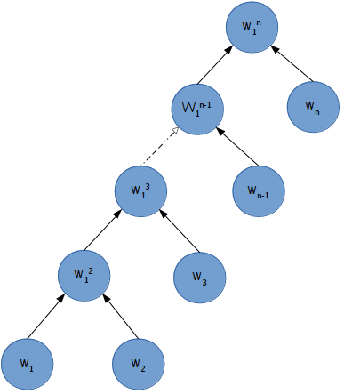
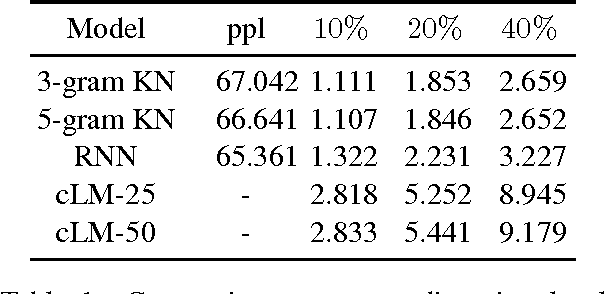
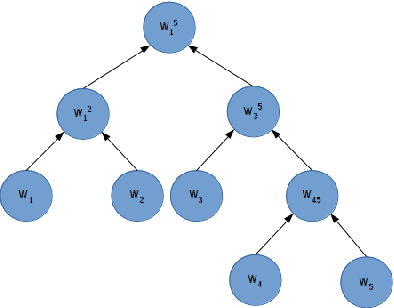

Traditional language models treat language as a finite state automaton on a probability space over words. This is a very strong assumption when modeling something inherently complex such as language. In this paper, we challenge this by showing how the linear chain assumption inherent in previous work can be translated into a sequential composition tree. We then propose a new model that marginalizes over all possible composition trees thereby removing any underlying structural assumptions. As the partition function of this new model is intractable, we use a recently proposed sentence level evaluation metric Contrastive Entropy to evaluate our model. Given this new evaluation metric, we report more than 100% improvement across distortion levels over current state of the art recurrent neural network based language models.