 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Complete Characterisation of ReLU-Invariant Distributions
Paper and Code
Dec 13, 2021
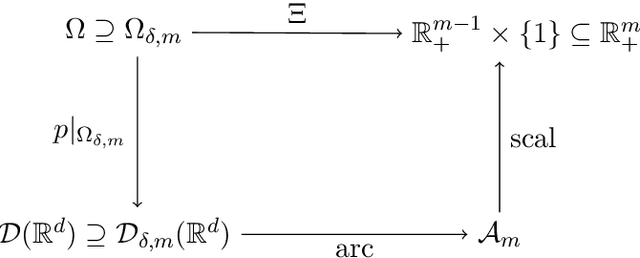
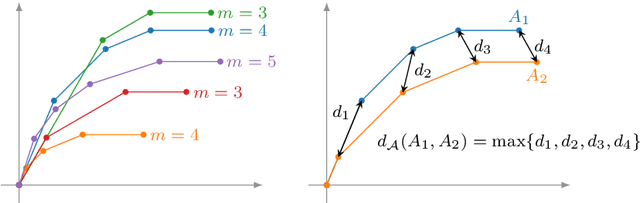
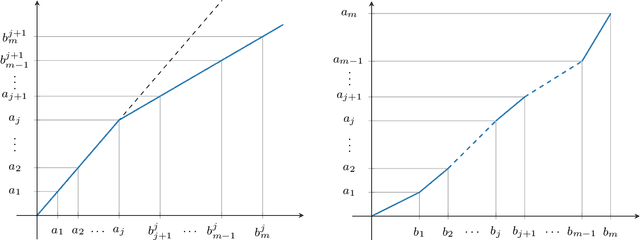
We give a complete characterisation of families of probability distributions that are invariant under the action of ReLU neural network layers. The need for such families arises during the training of Bayesian networks or the analysis of trained neural networks, e.g., in the context of uncertainty quantification (UQ) or explainable artificial intelligence (XAI). We prove that no invariant parametrised family of distributions can exist unless at least one of the following three restrictions holds: First, the network layers have a width of one, which is unreasonable for practical neural networks. Second, the probability measures in the family have finite support, which basically amounts to sampling distributions. Third, the parametrisation of the family is not locally Lipschitz continuous, which excludes all computationally feasible families. Finally, we show that these restrictions are individually necessary. For each of the three cases we can construct an invariant family exploiting exactly one of the restrictions but not the other two.