 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Network Traffic Representations for Novelty Detection
Paper and Code
Jun 30, 2020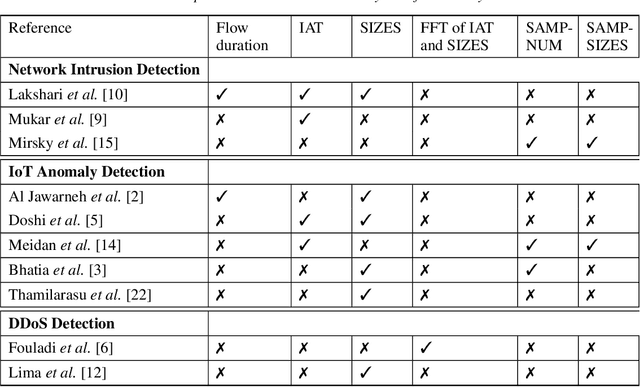
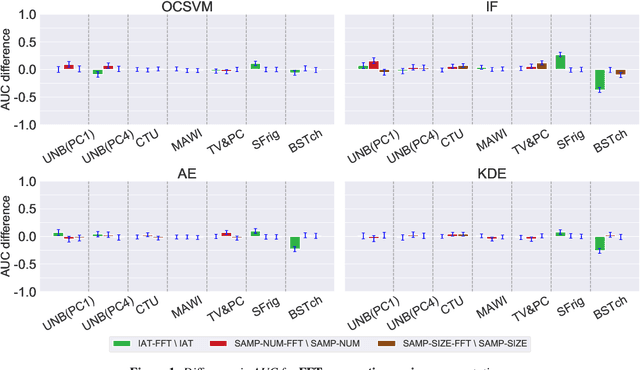
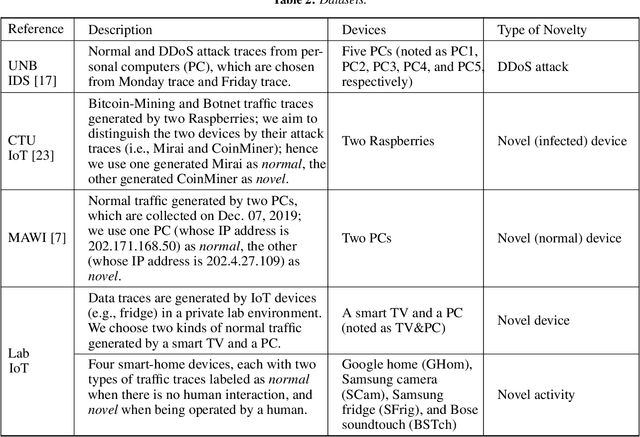
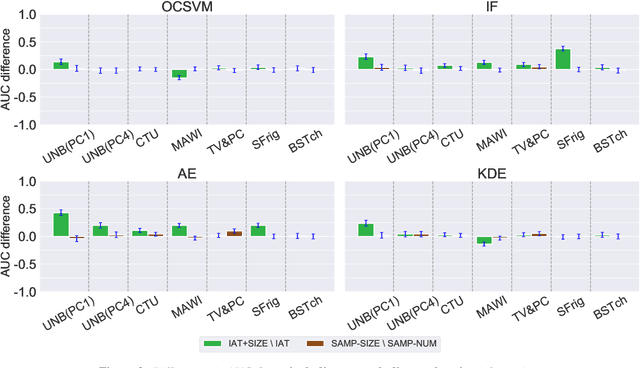
Data representation plays a critical role in the performance of novelty detection methods from machine learning (ML). Network traffic has conventionally posed many challenges to conventional anomaly detection, due to the inherent diversity of network traffic. Even within a single network, the most fundamental characteristics can change; this variability is fundamental to network traffic but especially true in the Internet of Things (IoT), where the network hosts a wide array of devices, each of which behaves differently, exhibiting high variance in both operational modalities and network activity patterns. Although there are established ways to study the effects of data representation in supervised learning, the problem is particularly challenging and understudied in the unsupervised learning context, where there is no standard way to evaluate the effect of selected features and representations at training time. This work explores different data representations for novelty detection in the Internet of Things, studying the effect of different representations of network traffic flows on the performance of a wide range of machine learning algorithms for novelty detection for problems arising in IoT, including malware detection, the detection of rogue devices, and the detection of cyberphysical anomalies. We find that no single representation works best (in terms of area under the curve) across devices or ML methods, yet the following features consistently improve the performance of novelty detection algorithms: (1) traffic sizes, (i.e., packet sizes rather than number of packets in volume-based representations); and (2) packet header fields (i.e., TTL, TCP flags).