 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA COLD Approach to Generating Optimal Samples
Paper and Code
May 23, 2019
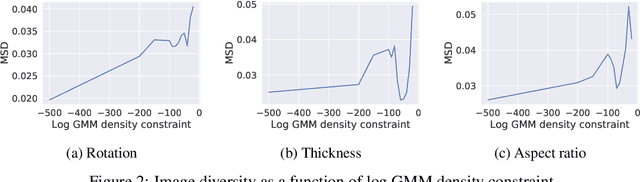
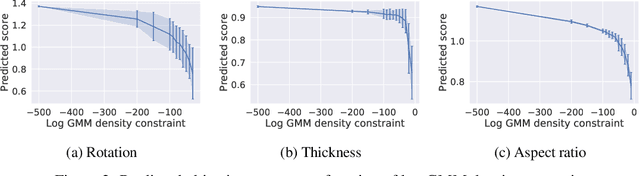
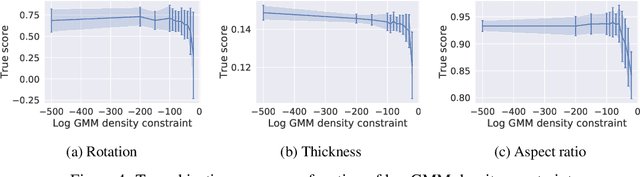
Optimising discrete data for a desired characteristic using gradient-based methods involves projecting the data into a continuous latent space and carrying out optimisation in this space. Carrying out global optimisation is difficult as optimisers are likely to follow gradients into regions of the latent space that the model has not been exposed to during training; samples generated from these regions are likely to be too dissimilar to the training data to be useful. We propose Constrained Optimisation with Latent Distributions (COLD), a constrained global optimisation procedure to find samples with high values of a desired property that are similar to yet distinct from the training data. We find that on MNIST, our procedure yields optima for each of three different objectives, and that enforcing tighter constraints improves the quality and increases the diversity of the generated images. On the ChEMBL molecular dataset, our method generates a diverse set of new molecules with drug-likeness scores similar to those of the highest-scoring molecules in the training data. We also demonstrate a computationally efficient way to approximate the constraint when evaluating it exactly is computationally expensive.