 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cheap Linear Attention Mechanism with Fast Lookups and Fixed-Size Representations
Paper and Code
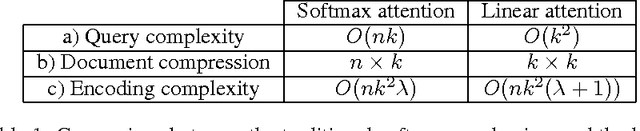
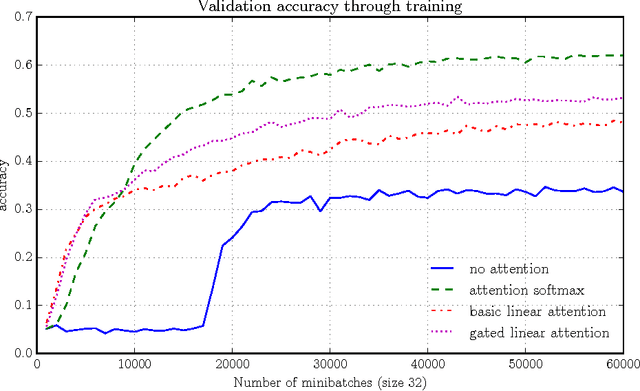
The softmax content-based attention mechanism has proven to be very beneficial in many applications of recurrent neural networks. Nevertheless it suffers from two major computational limitations. First, its computations for an attention lookup scale linearly in the size of the attended sequence. Second, it does not encode the sequence into a fixed-size representation but instead requires to memorize all the hidden states. These two limitations restrict the use of the softmax attention mechanism to relatively small-scale applications with short sequences and few lookups per sequence. In this work we introduce a family of linear attention mechanisms designed to overcome the two limitations listed above. We show that removing the softmax non-linearity from the traditional attention formulation yields constant-time attention lookups and fixed-size representations of the attended sequences. These properties make these linear attention mechanisms particularly suitable for large-scale applications with extreme query loads, real-time requirements and memory constraints. Early experiments on a question answering task show that these linear mechanisms yield significantly better accuracy results than no attention, but obviously worse than their softmax alternative.