 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Causal Linear Model to Quantify Edge Unfairness for Unfair Edge Prioritization and Discrimination Removal
Paper and Code
Jul 16, 2020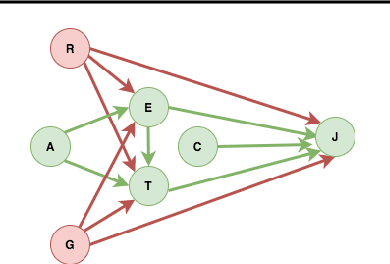
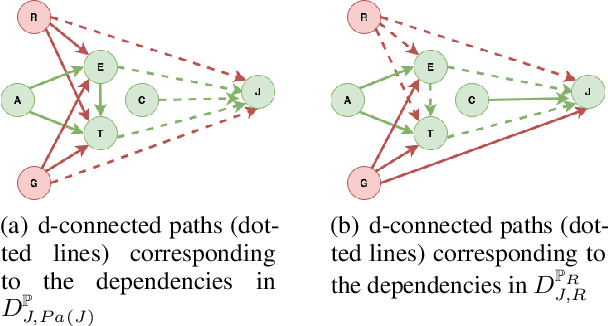
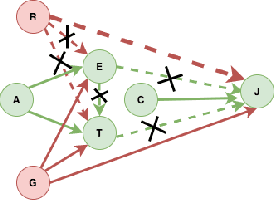
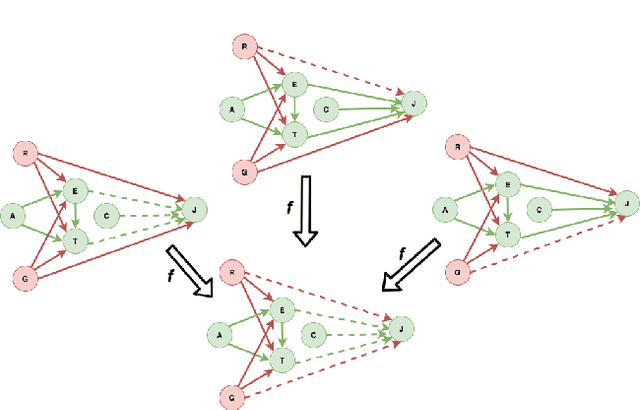
The dataset can be generated by an unfair mechanism in numerous settings. For instance, a judicial system is unfair if it rejects the bail plea of an accused based on the race. To mitigate the unfairness in the procedure generating the dataset, we need to know and quantify where the unfairness is originating from, how it affects the overall unfairness, and how to prioritize these sources of unfairness to address the real-world issues underlying these sources. Prior work of (Zhang, et al., 2017) identifies and removes discrimination after data is generated but does not suggest a methodology to mitigate unfairness in the data generation phase. We use the notion of an unfair edge, same as (Chiappa, et al., 2018), to be a source of discrimination and quantify unfairness along an unfair edge. We also quantify overall unfairness in a particular decision towards a subset of sensitive attributes in terms of edge unfairness and measure the sensitivity of the former when the latter is varied. Using the formulation of cumulative unfairness in terms of edge unfairness, we alter the discrimination removal methodology discussed in (Zhang, et al., 2017) by not formulating it as an optimization problem. This helps in getting rid of constraints that grow exponentially in the number of sensitive attributes and values taken by them. Finally, we discuss a priority algorithm for policymakers to address the real-world issues underlying the edges that result in unfairness. The experimental section validates the linear model assumption made to quantify edge unfairness.