Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Case Study on Pros and Cons of Regular Expression Detection and Dependency Parsing for Negation Extraction from German Medical Documents. Technical Report
Paper and Code
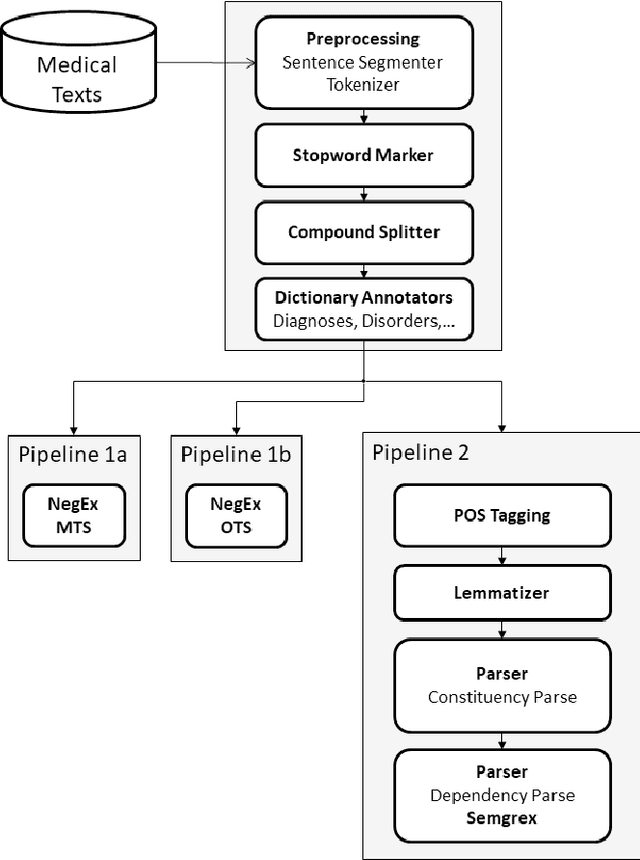

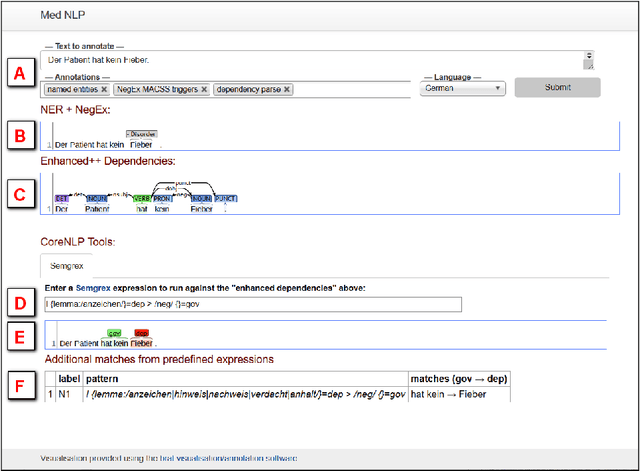
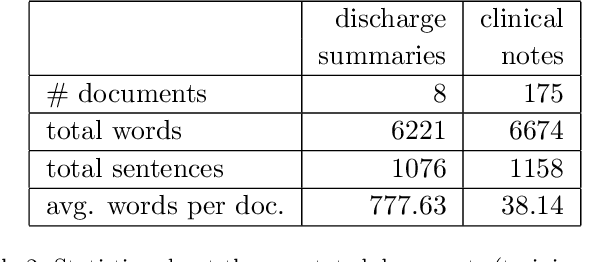
We describe our work on information extraction in medical documents written in German, especially detecting negations using an architecture based on the UIMA pipeline. Based on our previous work on software modules to cover medical concepts like diagnoses, examinations, etc. we employ a version of the NegEx regular expression algorithm with a large set of triggers as a baseline. We show how a significantly smaller trigger set is sufficient to achieve similar results, in order to reduce adaptation times to new text types. We elaborate on the question whether dependency parsing (based on the Stanford CoreNLP model) is a good alternative and describe the potentials and shortcomings of both approaches.
* 30 pages
View paper on