 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Balanced Data Approach for Evaluating Cross-Lingual Transfer: Mapping the Linguistic Blood Bank
Paper and Code
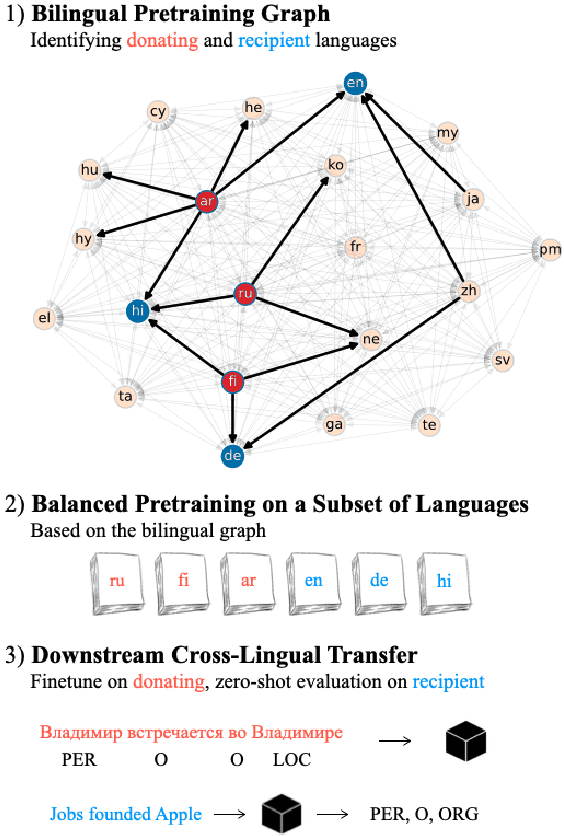
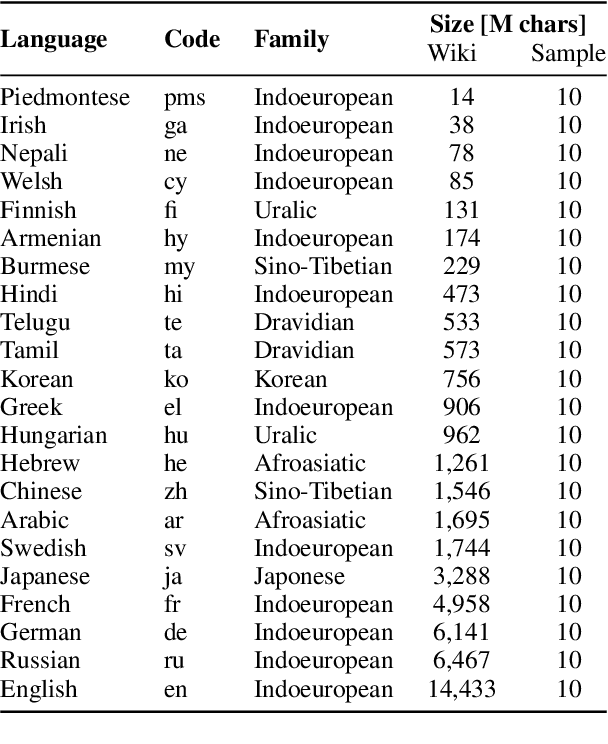
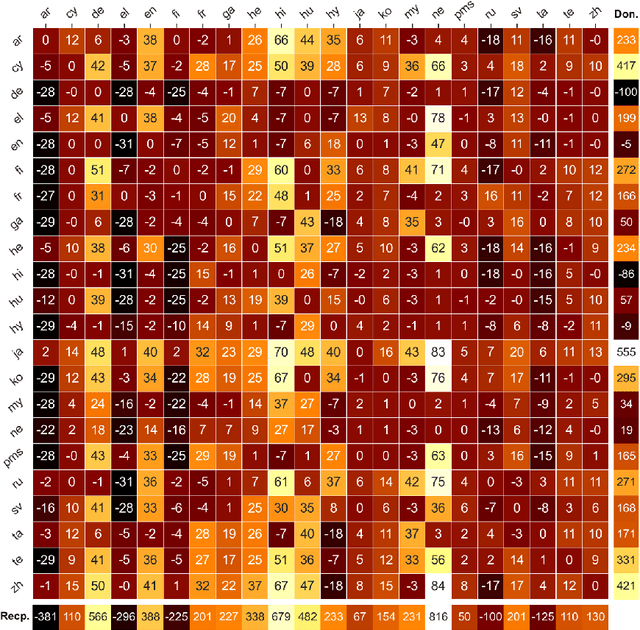

We show that the choice of pretraining languages affects downstream cross-lingual transfer for BERT-based models. We inspect zero-shot performance in balanced data conditions to mitigate data size confounds, classifying pretraining languages that improve downstream performance as donors, and languages that are improved in zero-shot performance as recipients. We develop a method of quadratic time complexity in the number of languages to estimate these relations, instead of an exponential exhaustive computation of all possible combinations. We find that our method is effective on a diverse set of languages spanning different linguistic features and two downstream tasks. Our findings can inform developers of large-scale multilingual language models in choosing better pretraining configurations.