 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4+3 Phases of Compute-Optimal Neural Scaling Laws
Paper and Code
May 23, 2024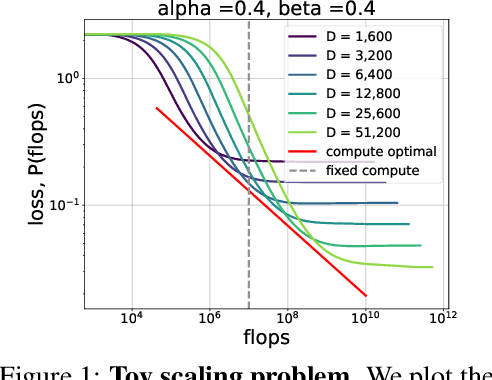

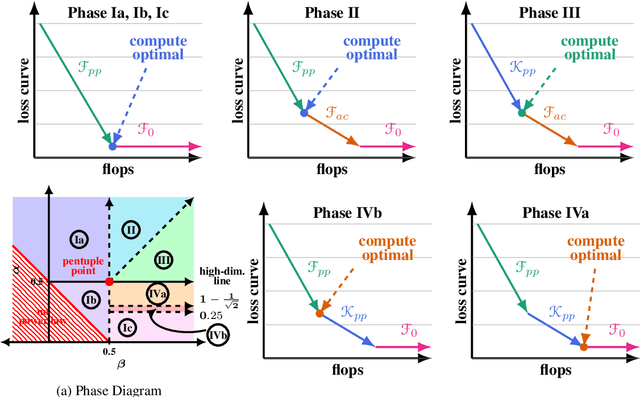

We consider the three parameter solvable neural scaling model introduced by Maloney, Roberts, and Sully. The model has three parameters: data complexity, target complexity, and model-parameter-count. We use this neural scaling model to derive new predictions about the compute-limited, infinite-data scaling law regime. To train the neural scaling model, we run one-pass stochastic gradient descent on a mean-squared loss. We derive a representation of the loss curves which holds over all iteration counts and improves in accuracy as the model parameter count grows. We then analyze the compute-optimal model-parameter-count, and identify 4 phases (+3 subphases) in the data-complexity/target-complexity phase-plane. The phase boundaries are determined by the relative importance of model capacity, optimizer noise, and embedding of the features. We furthermore derive, with mathematical proof and extensive numerical evidence, the scaling-law exponents in all of these phases, in particular computing the optimal model-parameter-count as a function of floating point operation budget.