Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Point Cloud Registration with Multi-Scale Architecture and Self-supervised Fine-tuning
Paper and Code

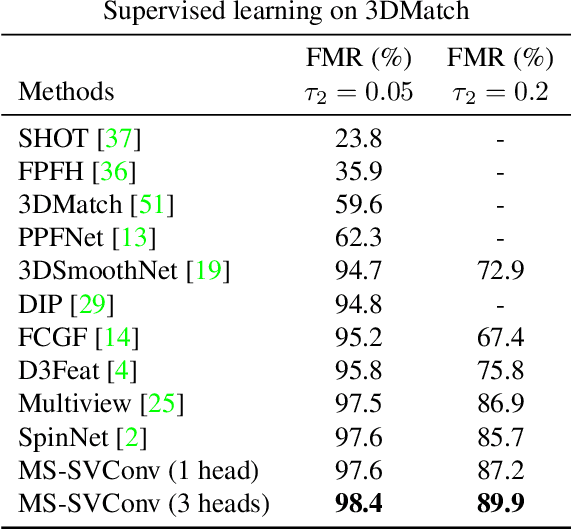
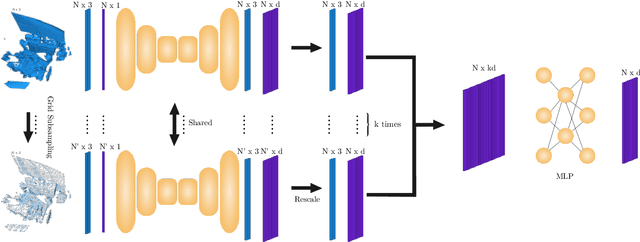

We present MS-SVConv, a fast multi-scale deep neural network that outputs features from point clouds for 3D registration between two scenes. We compute features using a 3D sparse voxel convolutional network on a point cloud at different scales and then fuse the features through fully-connected layers. With supervised learning, we show significant improvements compared to state-of-the-art methods on the competitive and well-known 3DMatch benchmark. We also achieve a better generalization through different source and target datasets, with very fast computation. Finally, we present a strategy to fine-tune MS-SVConv on unknown datasets in a self-supervised way, which leads to state-of-the-art results on ETH and TUM datasets.
View paper on