 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1-bit LAMB: Communication Efficient Large-Scale Large-Batch Training with LAMB's Convergence Speed
Paper and Code

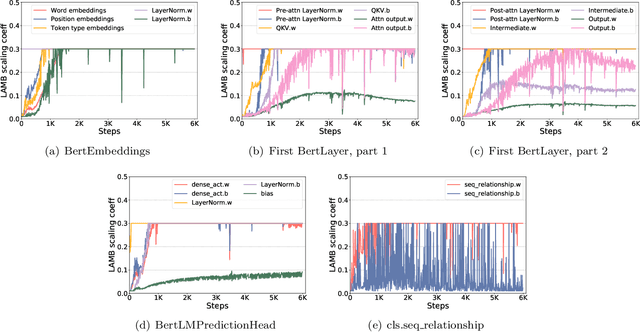
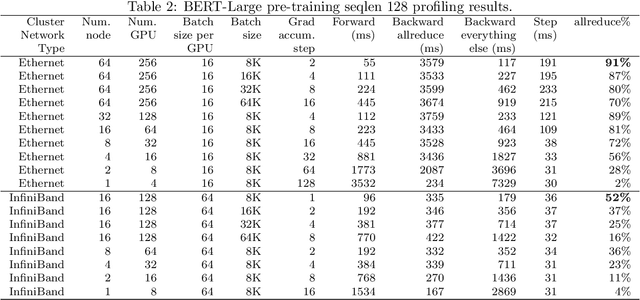

To train large models (like BERT and GPT-3) with hundreds or even thousands of GPUs, the communication has become a major bottleneck, especially on commodity systems with limited-bandwidth TCP interconnects network. On one side large-batch optimization such as LAMB algorithm was proposed to reduce the number of communications. On the other side, communication compression algorithms such as 1-bit SGD and 1-bit Adam help to reduce the volume of each communication. However, we find that simply using one of the techniques is not sufficient to solve the communication challenge, especially on low-bandwidth Ethernet networks. Motivated by this we aim to combine the power of large-batch optimization and communication compression, but we find that existing compression strategies cannot be directly applied to LAMB due to its unique adaptive layerwise learning rates. To this end, we design a new communication-efficient algorithm, 1-bit LAMB, which introduces a novel way to support adaptive layerwise learning rates even when communication is compressed. In addition, we introduce a new system implementation for compressed communication using the NCCL backend of PyTorch distributed, which improves both usability and performance compared to existing MPI-based implementation. For BERT-Large pre-training task with batch sizes from 8K to 64K, our evaluations on up to 256 GPUs demonstrate that 1-bit LAMB with NCCL-based backend is able to achieve up to 4.6x communication volume reduction, up to 2.8x end-to-end speedup (in terms of number of training samples per second), and the same convergence speed (in terms of number of pre-training samples to reach the same accuracy on fine-tuning tasks) compared to uncompressed LAMB.