 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTetris: Re-architecting Convolutional Neural Network Computation for Machine Learning Accelerators
Nov 14, 2018
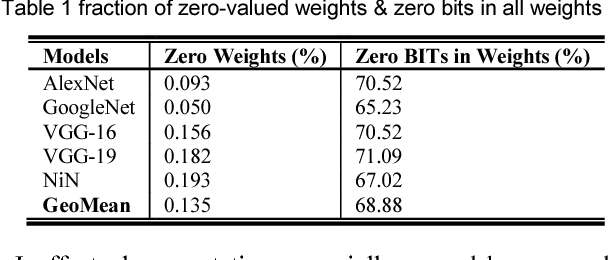
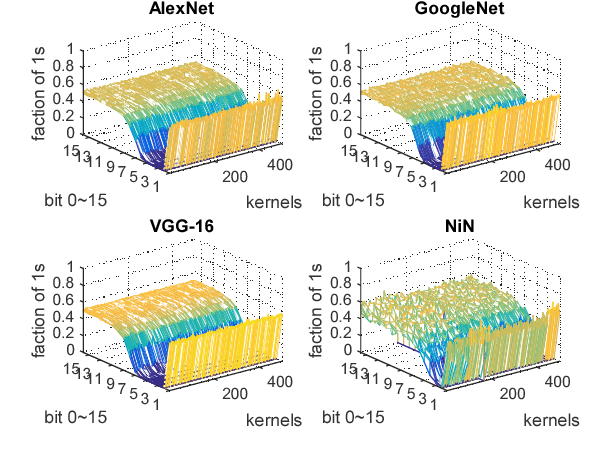

Inference efficiency is the predominant consideration in designing deep learning accelerators. Previous work mainly focuses on skipping zero values to deal with remarkable ineffectual computation, while zero bits in non-zero values, as another major source of ineffectual computation, is often ignored. The reason lies on the difficulty of extracting essential bits during operating multiply-and-accumulate (MAC) in the processing element. Based on the fact that zero bits occupy as high as 68.9% fraction in the overall weights of modern deep convolutional neural network models, this paper firstly proposes a weight kneading technique that could eliminate ineffectual computation caused by either zero value weights or zero bits in non-zero weights, simultaneously. Besides, a split-and-accumulate (SAC) computing pattern in replacement of conventional MAC, as well as the corresponding hardware accelerator design called Tetris are proposed to support weight kneading at the hardware level. Experimental results prove that Tetris could speed up inference up to 1.50x, and improve power efficiency up to 5.33x compared with the state-of-the-art baselines.