 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask-Guided Multi-Task Network for Face Attribute Recognition
Jan 04, 2026Face Attribute Recognition (FAR) plays a crucial role in applications such as person re-identification, face retrieval, and face editing. Conventional multi-task attribute recognition methods often process the entire feature map for feature extraction and attribute classification, which can produce redundant features due to reliance on global regions. To address these challenges, we propose a novel approach emphasizing the selection of specific feature regions for efficient feature learning. We introduce the Mask-Guided Multi-Task Network (MGMTN), which integrates Adaptive Mask Learning (AML) and Group-Global Feature Fusion (G2FF) to address the aforementioned limitations. Leveraging a pre-trained keypoint annotation model and a fully convolutional network, AML accurately localizes critical facial parts (e.g., eye and mouth groups) and generates group masks that delineate meaningful feature regions, thereby mitigating negative transfer from global region usage. Furthermore, G2FF combines group and global features to enhance FAR learning, enabling more precise attribute identification. Extensive experiments on two challenging facial attribute recognition datasets demonstrate the effectiveness of MGMTN in improving FAR performance.
Modification Takes Courage: Seamless Image Stitching via Reference-Driven Inpainting
Nov 15, 2024



Current image stitching methods often produce noticeable seams in challenging scenarios such as uneven hue and large parallax. To tackle this problem, we propose the Reference-Driven Inpainting Stitcher (RDIStitcher), which reformulates the image fusion and rectangling as a reference-based inpainting model, incorporating a larger modification fusion area and stronger modification intensity than previous methods. Furthermore, we introduce a self-supervised model training method, which enables the implementation of RDIStitcher without requiring labeled data by fine-tuning a Text-to-Image (T2I) diffusion model. Recognizing difficulties in assessing the quality of stitched images, we present the Multimodal Large Language Models (MLLMs)-based metrics, offering a new perspective on evaluating stitched image quality. Compared to the state-of-the-art (SOTA) method, extensive experiments demonstrate that our method significantly enhances content coherence and seamless transitions in the stitched images. Especially in the zero-shot experiments, our method exhibits strong generalization capabilities. Code: https://github.com/yayoyo66/RDIStitcher
Streamlining the Image Stitching Pipeline: Integrating Fusion and Rectangling into a Unified Model
Apr 23, 2024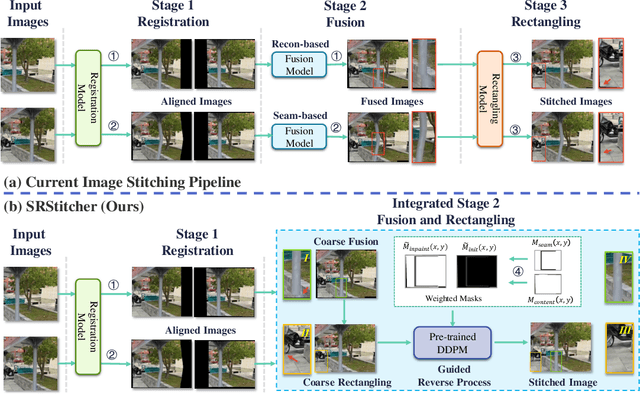
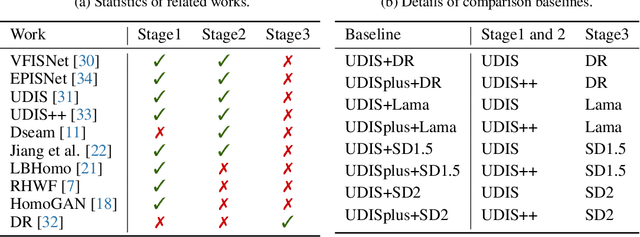
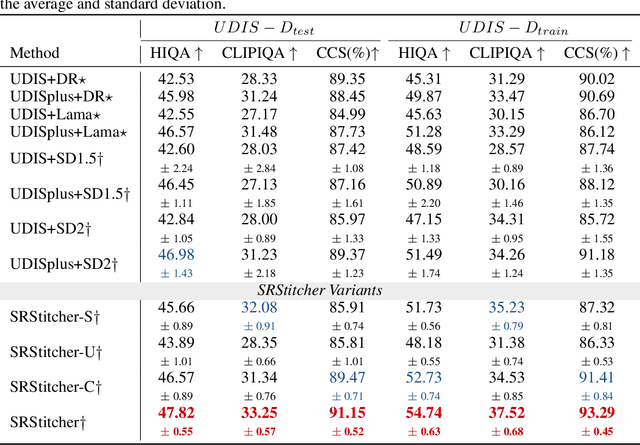

Learning-based image stitching techniques typically involve three distinct stages: registration, fusion, and rectangling. These stages are often performed sequentially, each trained independently, leading to potential cascading error propagation and complex parameter tuning challenges. In rethinking the mathematical modeling of the fusion and rectangling stages, we discovered that these processes can be effectively combined into a single, variety-intensity inpainting problem. Therefore, we propose the Simple and Robust Stitcher (SRStitcher), an efficient training-free image stitching method that merges the fusion and rectangling stages into a unified model. By employing the weighted mask and large-scale generative model, SRStitcher can solve the fusion and rectangling problems in a single inference, without additional training or fine-tuning of other models. Our method not only simplifies the stitching pipeline but also enhances fault tolerance towards misregistration errors. Extensive experiments demonstrate that SRStitcher outperforms state-of-the-art (SOTA) methods in both quantitative assessments and qualitative evaluations. The code is released at https://github.com/yayoyo66/SRStitcher