 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Guided Dynamic Sparsification for Pre-Trained Model-based Class-Incremental Learning
Jan 29, 2026Class-Incremental Learning (CIL) requires a model to continually learn new classes without forgetting old ones. A common and efficient solution freezes a pre-trained model and employs lightweight adapters, whose parameters are often forced to be orthogonal to prevent inter-task interference. However, we argue that this parameter-constraining method is detrimental to plasticity. To this end, we propose Semantic-Guided Dynamic Sparsification (SGDS), a novel method that proactively guides the activation space by governing the orientation and rank of its subspaces through targeted sparsification. Specifically, SGDS promotes knowledge transfer by encouraging similar classes to share a compact activation subspace, while simultaneously preventing interference by assigning non-overlapping activation subspaces to dissimilar classes. By sculpting class-specific sparse subspaces in the activation space, SGDS effectively mitigates interference without imposing rigid constraints on the parameter space. Extensive experiments on various benchmark datasets demonstrate the state-of-the-art performance of SGDS.
Dynamical Adapter Fusion: Constructing A Global Adapter for Pre-Trained Model-based Class-Incremental Learning
Jan 29, 2026Class-Incremental Learning (CIL) requires models to continuously acquire new classes without forgetting previously learned ones. A dominant paradigm involves freezing a pre-trained model and training lightweight, task-specific adapters. However, maintaining task-specific parameters hinders knowledge transfer and incurs high retrieval costs, while naive parameter fusion often leads to destructive interference and catastrophic forgetting. To address these challenges, we propose Dynamical Adapter Fusion (DAF) to construct a single robust global adapter. Grounded in the PAC-Bayes theorem, we derive a fusion mechanism that explicitly integrates three components: the optimized task-specific adapter parameters, the previous global adapter parameters, and the initialization parameters. We utilize the Taylor expansion of the loss function to derive the optimal fusion coefficients, dynamically achieving the best balance between stability and plasticity. Furthermore, we propose a Robust Initialization strategy to effectively capture global knowledge patterns. Experiments on multiple CIL benchmarks demonstrate that DAF achieves state-of-the-art (SOTA) performance.
Overcoming Prompts Pool Confusion via Parameterized Prompt for Incremental Object Detection
Oct 31, 2025Recent studies have demonstrated that incorporating trainable prompts into pretrained models enables effective incremental learning. However, the application of prompts in incremental object detection (IOD) remains underexplored. Existing prompts pool based approaches assume disjoint class sets across incremental tasks, which are unsuitable for IOD as they overlook the inherent co-occurrence phenomenon in detection images. In co-occurring scenarios, unlabeled objects from previous tasks may appear in current task images, leading to confusion in prompts pool. In this paper, we hold that prompt structures should exhibit adaptive consolidation properties across tasks, with constrained updates to prevent catastrophic forgetting. Motivated by this, we introduce Parameterized Prompts for Incremental Object Detection (P$^2$IOD). Leveraging neural networks global evolution properties, P$^2$IOD employs networks as the parameterized prompts to adaptively consolidate knowledge across tasks. To constrain prompts structure updates, P$^2$IOD further engages a parameterized prompts fusion strategy. Extensive experiments on PASCAL VOC2007 and MS COCO datasets demonstrate that P$^2$IOD's effectiveness in IOD and achieves the state-of-the-art performance among existing baselines.
CBPNet: A Continual Backpropagation Prompt Network for Alleviating Plasticity Loss on Edge Devices
Sep 19, 2025To meet the demands of applications like robotics and autonomous driving that require real-time responses to dynamic environments, efficient continual learning methods suitable for edge devices have attracted increasing attention. In this transition, using frozen pretrained models with prompts has become a mainstream strategy to combat catastrophic forgetting. However, this approach introduces a new critical bottleneck: plasticity loss, where the model's ability to learn new knowledge diminishes due to the frozen backbone and the limited capacity of prompt parameters. We argue that the reduction in plasticity stems from a lack of update vitality in underutilized parameters during the training process. To this end, we propose the Continual Backpropagation Prompt Network (CBPNet), an effective and parameter efficient framework designed to restore the model's learning vitality. We innovatively integrate an Efficient CBP Block that counteracts plasticity decay by adaptively reinitializing these underutilized parameters. Experimental results on edge devices demonstrate CBPNet's effectiveness across multiple benchmarks. On Split CIFAR-100, it improves average accuracy by over 1% against a strong baseline, and on the more challenging Split ImageNet-R, it achieves a state of the art accuracy of 69.41%. This is accomplished by training additional parameters that constitute less than 0.2% of the backbone's size, validating our approach.
Continual Learning in the Frequency Domain
Oct 10, 2024



Continual learning (CL) is designed to learn new tasks while preserving existing knowledge. Replaying samples from earlier tasks has proven to be an effective method to mitigate the forgetting of previously acquired knowledge. However, the current research on the training efficiency of rehearsal-based methods is insufficient, which limits the practical application of CL systems in resource-limited scenarios. The human visual system (HVS) exhibits varying sensitivities to different frequency components, enabling the efficient elimination of visually redundant information. Inspired by HVS, we propose a novel framework called Continual Learning in the Frequency Domain (CLFD). To our knowledge, this is the first study to utilize frequency domain features to enhance the performance and efficiency of CL training on edge devices. For the input features of the feature extractor, CLFD employs wavelet transform to map the original input image into the frequency domain, thereby effectively reducing the size of input feature maps. Regarding the output features of the feature extractor, CLFD selectively utilizes output features for distinct classes for classification, thereby balancing the reusability and interference of output features based on the frequency domain similarity of the classes across various tasks. Optimizing only the input and output features of the feature extractor allows for seamless integration of CLFD with various rehearsal-based methods. Extensive experiments conducted in both cloud and edge environments demonstrate that CLFD consistently improves the performance of state-of-the-art (SOTA) methods in both precision and training efficiency. Specifically, CLFD can increase the accuracy of the SOTA CL method by up to 6.83% and reduce the training time by 2.6$\times$.
EGOR: Efficient Generated Objects Replay for incremental object detection
Jun 07, 2024

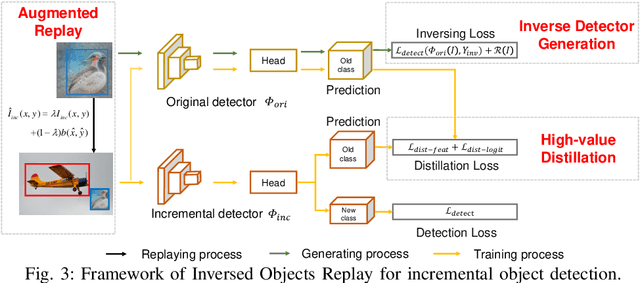

Incremental object detection aims to simultaneously maintain old-class accuracy and detect emerging new-class objects in incremental data. Most existing distillation-based methods underperform when unlabeled old-class objects are absent in the incremental dataset. While the absence can be mitigated by generating old-class samples, it also incurs high computational costs. In this paper, we argue that the extra computational cost stems from the inconsistency between the detector and the generative model, along with redundant generation. To overcome this problem, we propose Efficient Generated Object Replay (EGOR). Specifically, we generate old-class samples by inversing the original detectors, thus eliminating the necessity of training and storing additional generative models. We also propose augmented replay to reuse the objects in generated samples, thereby reducing the redundant generation. In addition, we propose high-response knowledge distillation focusing on the knowledge related to the old class, which transfers the knowledge in generated objects to the incremental detector. With the addition of the generated objects and losses, we observe a bias towards old classes in the detector. We balance the losses for old and new classes to alleviate the bias, thereby increasing the overall detection accuracy. Extensive experiments conducted on MS COCO 2017 demonstrate that our method can efficiently improve detection performance in the absence of old-class objects.