Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJ2N -- Nominal Adjective Identification and its Application
Sep 26, 2024
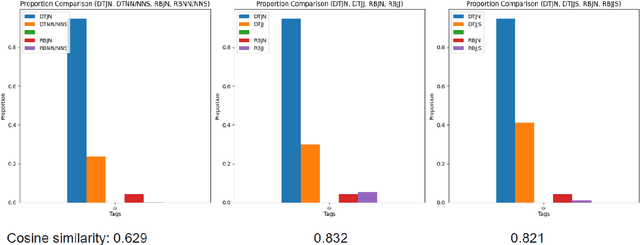
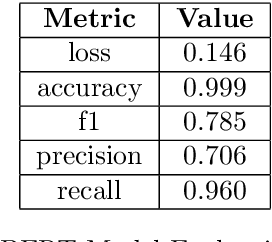
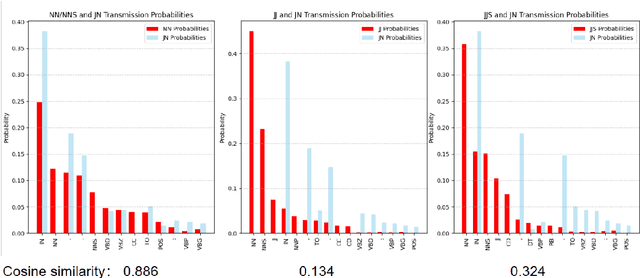
This paper explores the challenges posed by nominal adjectives (NAs) in natural language processing (NLP) tasks, particularly in part-of-speech (POS) tagging. We propose treating NAs as a distinct POS tag, "JN," and investigate its impact on POS tagging, BIO chunking, and coreference resolution. Our study shows that reclassifying NAs can improve the accuracy of syntactic analysis and structural understanding in NLP. We present experimental results using Hidden Markov Models (HMMs), Maximum Entropy (MaxEnt) models, and Spacy, demonstrating the feasibility and potential benefits of this approach. Additionally we trained a bert model to identify the NA in untagged text.
* 7 pages, 4 figures
Via