 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Hardness-driven Augmentation and Alignment Strategies for Multi-Source Domain Adaptations
Jan 02, 2025Multi-source Domain Adaptation (MDA) aims to transfer knowledge from multiple labeled source domains to an unlabeled target domain. Nevertheless, traditional methods primarily focus on achieving inter-domain alignment through sample-level constraints, such as Maximum Mean Discrepancy (MMD), neglecting three pivotal aspects: 1) the potential of data augmentation, 2) the significance of intra-domain alignment, and 3) the design of cluster-level constraints. In this paper, we introduce a novel hardness-driven strategy for MDA tasks, named "A3MDA" , which collectively considers these three aspects through Adaptive hardness quantification and utilization in both data Augmentation and domain Alignment.To achieve this, "A3MDA" progressively proposes three Adaptive Hardness Measurements (AHM), i.e., Basic, Smooth, and Comparative AHMs, each incorporating distinct mechanisms for diverse scenarios. Specifically, Basic AHM aims to gauge the instantaneous hardness for each source/target sample. Then, hardness values measured by Smooth AHM will adaptively adjust the intensity level of strong data augmentation to maintain compatibility with the model's generalization capacity.In contrast, Comparative AHM is designed to facilitate cluster-level constraints. By leveraging hardness values as sample-specific weights, the traditional MMD is enhanced into a weighted-clustered variant, strengthening the robustness and precision of inter-domain alignment. As for the often-neglected intra-domain alignment, we adaptively construct a pseudo-contrastive matrix by selecting harder samples based on the hardness rankings, enhancing the quality of pseudo-labels, and shaping a well-clustered target feature space. Experiments on multiple MDA benchmarks show that " A3MDA " outperforms other methods.
Judge Like a Real Doctor: Dual Teacher Sample Consistency Framework for Semi-supervised Medical Image Classification
Nov 05, 2024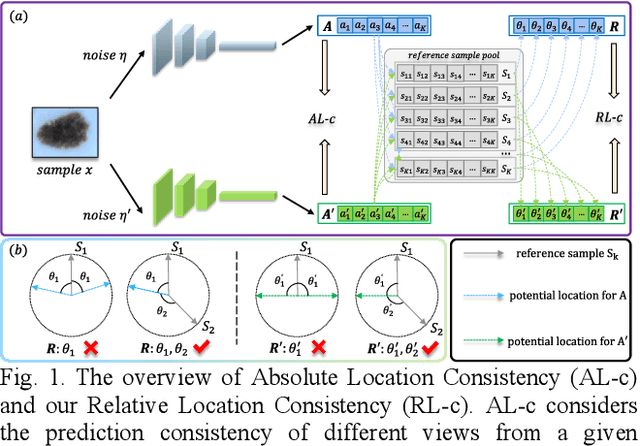
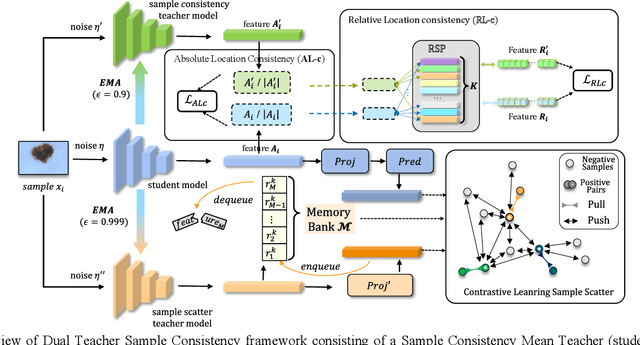
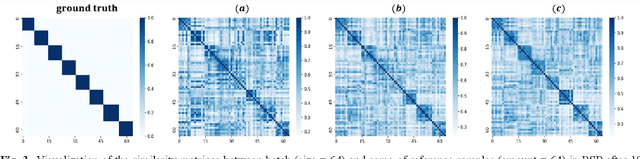
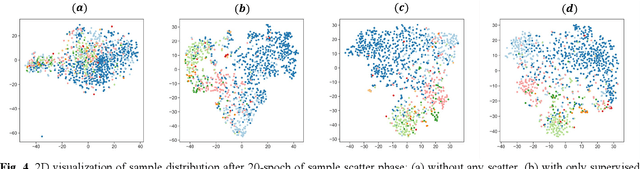
Semi-supervised learning (SSL) is a popular solution to alleviate the high annotation cost in medical image classification. As a main branch of SSL, consistency regularization engages in imposing consensus between the predictions of a single sample from different views, termed as Absolute Location consistency (AL-c). However, only AL-c may be insufficient. Just like when diagnosing a case in practice, besides the case itself, the doctor usually refers to certain related trustworthy cases to make more reliable decisions.Therefore, we argue that solely relying on AL-c may ignore the relative differences across samples, which we interpret as relative locations, and only exploit limited information from one perspective. To address this issue, we propose a Sample Consistency Mean Teacher (SCMT) which not only incorporates AL c but also additionally enforces consistency between the samples' relative similarities to its related samples, called Relative Location consistency (RL c). AL c and RL c conduct consistency regularization from two different perspectives, jointly extracting more diverse semantic information for classification. On the other hand, due to the highly similar structures in medical images, the sample distribution could be overly dense in feature space, making their relative locations susceptible to noise. To tackle this problem, we further develop a Sample Scatter Mean Teacher (SSMT) by utilizing contrastive learning to sparsify the sample distribution and obtain robust and effective relative locations. Extensive experiments on different datasets demonstrate the superiority of our method.