 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacteristic Regularisation for Super-Resolving Face Images
Dec 30, 2019
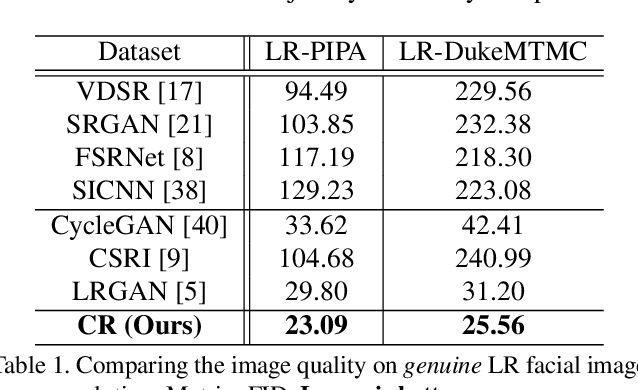
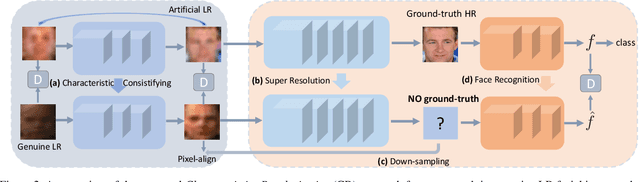
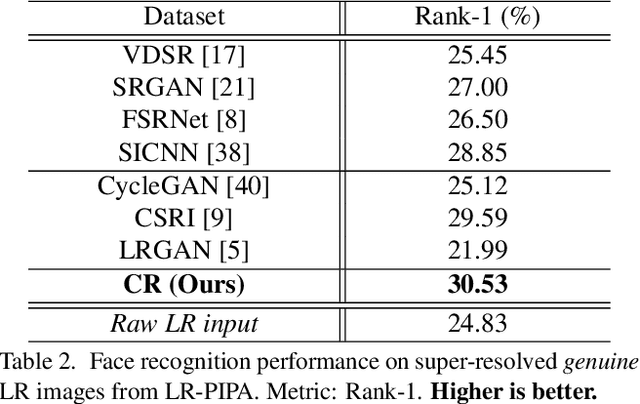
Existing facial image super-resolution (SR) methods focus mostly on improving artificially down-sampled low-resolution (LR) imagery. Such SR models, although strong at handling artificial LR images, often suffer from significant performance drop on genuine LR test data. Previous unsupervised domain adaptation (UDA) methods address this issue by training a model using unpaired genuine LR and HR data as well as cycle consistency loss formulation. However, this renders the model overstretched with two tasks: consistifying the visual characteristics and enhancing the image resolution. Importantly, this makes the end-to-end model training ineffective due to the difficulty of back-propagating gradients through two concatenated CNNs. To solve this problem, we formulate a method that joins the advantages of conventional SR and UDA models. Specifically, we separate and control the optimisations for characteristics consistifying and image super-resolving by introducing Characteristic Regularisation (CR) between them. This task split makes the model training more effective and computationally tractable. Extensive evaluations demonstrate the performance superiority of our method over state-of-the-art SR and UDA models on both genuine and artificial LR facial imagery data.
Low-Resolution Face Recognition
Nov 21, 2018
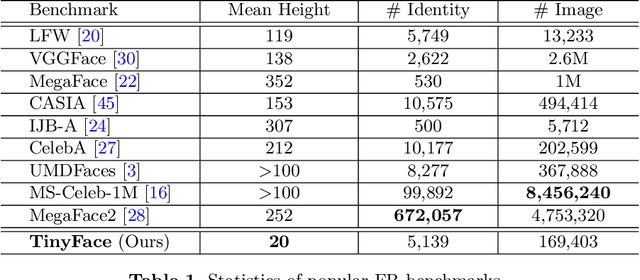
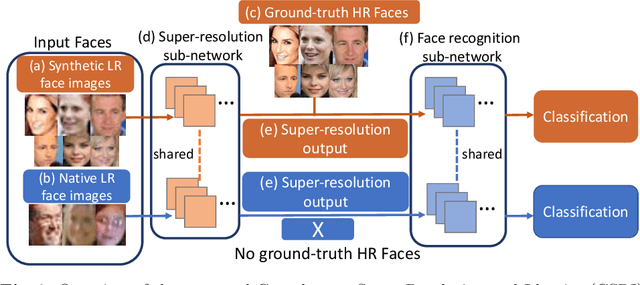

Whilst recent face-recognition (FR) techniques have made significant progress on recognising constrained high-resolution web images, the same cannot be said on natively unconstrained low-resolution images at large scales. In this work, we examine systematically this under-studied FR problem, and introduce a novel Complement Super-Resolution and Identity (CSRI) joint deep learning method with a unified end-to-end network architecture. We further construct a new large-scale dataset TinyFace of native unconstrained low-resolution face images from selected public datasets, because none benchmark of this nature exists in the literature. With extensive experiments we show there is a significant gap between the reported FR performances on popular benchmarks and the results on TinyFace, and the advantages of the proposed CSRI over a variety of state-of-the-art FR and super-resolution deep models on solving this largely ignored FR scenario. The TinyFace dataset is released publicly at: https://qmul-tinyface.github.io/.
Surveillance Face Recognition Challenge
Aug 29, 2018
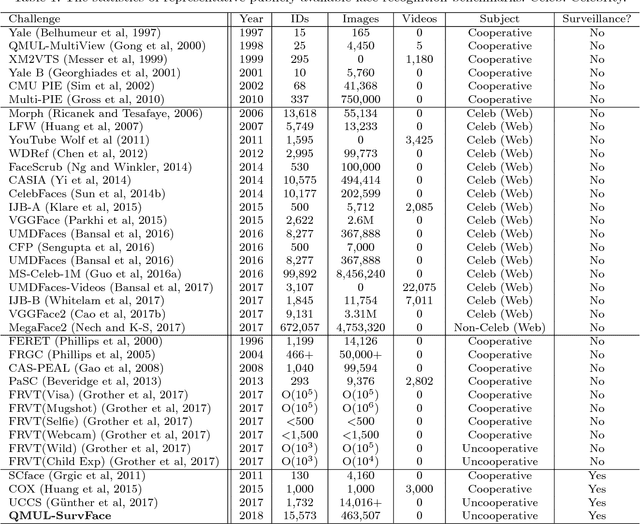
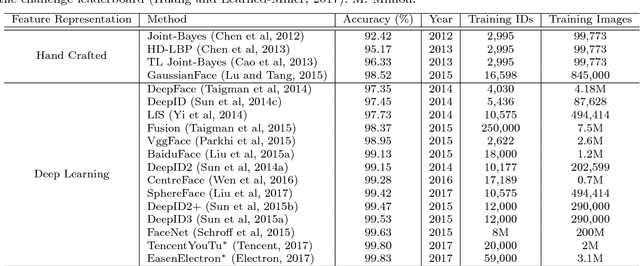
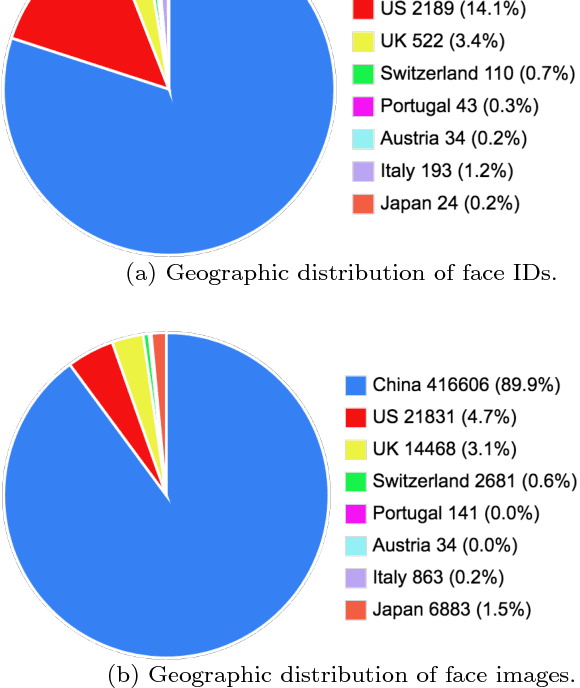
Face recognition (FR) is one of the most extensively investigated problems in computer vision. Significant progress in FR has been made due to the recent introduction of the larger scale FR challenges, particularly with constrained social media web images, e.g. high-resolution photos of celebrity faces taken by professional photo-journalists. However, the more challenging FR in unconstrained and low-resolution surveillance images remains largely under-studied. To facilitate more studies on developing FR models that are effective and robust for low-resolution surveillance facial images, we introduce a new Surveillance Face Recognition Challenge, which we call the QMUL-SurvFace benchmark. This new benchmark is the largest and more importantly the only true surveillance FR benchmark to our best knowledge, where low-resolution images are not synthesised by artificial down-sampling of native high-resolution images. This challenge contains 463,507 face images of 15,573 distinct identities captured in real-world uncooperative surveillance scenes over wide space and time. As a consequence, it presents an extremely challenging FR benchmark. We benchmark the FR performance on this challenge using five representative deep learning face recognition models, in comparison to existing benchmarks. We show that the current state of the arts are still far from being satisfactory to tackle the under-investigated surveillance FR problem in practical forensic scenarios. Face recognition is generally more difficult in an open-set setting which is typical for surveillance scenarios, owing to a large number of non-target people (distractors) appearing open spaced scenes. This is evidently so that on the new Surveillance FR Challenge, the top-performing CentreFace deep learning FR model on the MegaFace benchmark can now only achieve 13.2% success rate (at Rank-20) at a 10% false alarm rate.