 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Depth Decoding: Faster Speculative Decoding for LLMs
Aug 30, 2024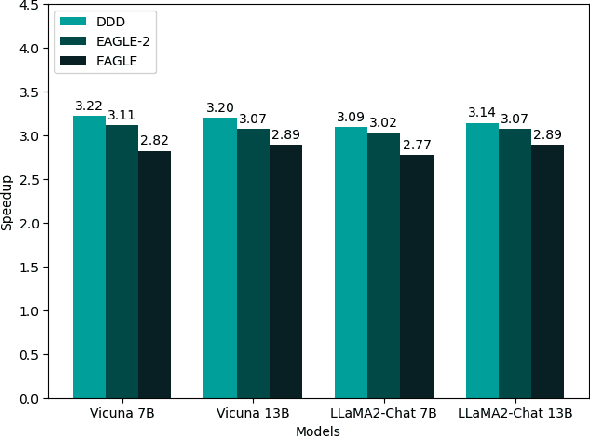
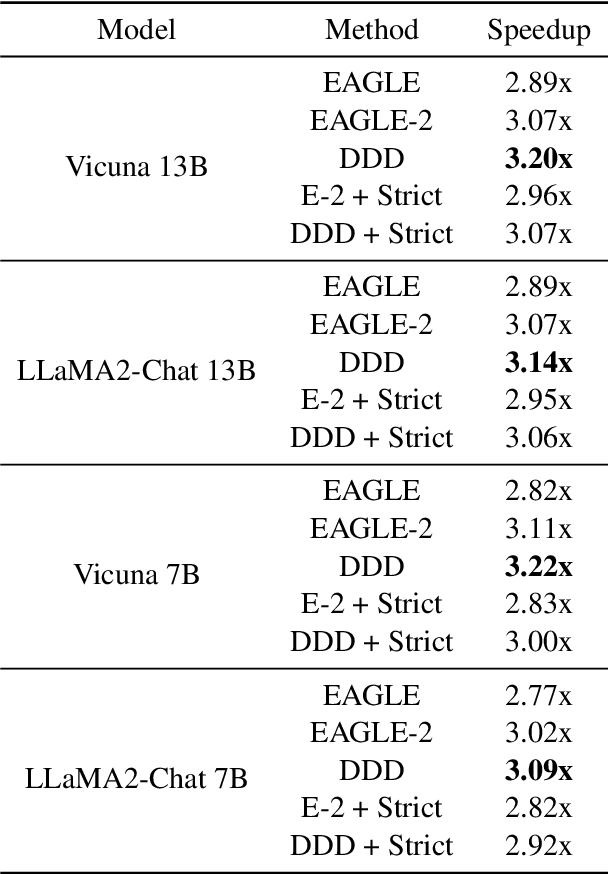
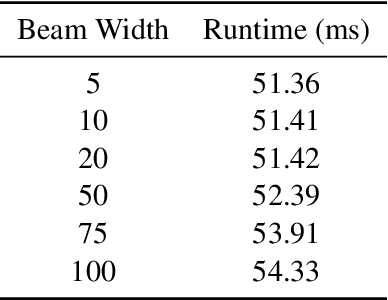
The acceleration of Large Language Models (LLMs) with speculative decoding provides a significant runtime improvement without any loss of accuracy. Currently, EAGLE-2 is the state-of-the-art speculative decoding method, improving on EAGLE with a dynamic draft tree. We introduce Dynamic Depth Decoding (DDD), which optimises EAGLE-2's tree drafting method using a dynamic depth. This extends the average speedup that EAGLE-2 achieves over EAGLE by $44\%$, giving DDD an average speedup of $3.16$x.
Using fine-tuning and min lookahead beam search to improve Whisper
Sep 19, 2023



The performance of Whisper in low-resource languages is still far from perfect. In addition to a lack of training data on low-resource languages, we identify some limitations in the beam search algorithm used in Whisper. To address these issues, we fine-tune Whisper on additional data and propose an improved decoding algorithm. On the Vietnamese language, fine-tuning Whisper-Tiny with LoRA leads to an improvement of 38.49 in WER over the zero-shot Whisper-Tiny setting which is a further reduction of 1.45 compared to full-parameter fine-tuning. Additionally, by using Filter-Ends and Min Lookahead decoding algorithms, the WER reduces by 2.26 on average over a range of languages compared to standard beam search. These results generalise to larger Whisper model sizes. We also prove a theorem that Min Lookahead outperforms the standard beam search algorithm used in Whisper.