 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPGA-based Acceleration of Neural Network for Image Classification using Vitis AI
Dec 30, 2024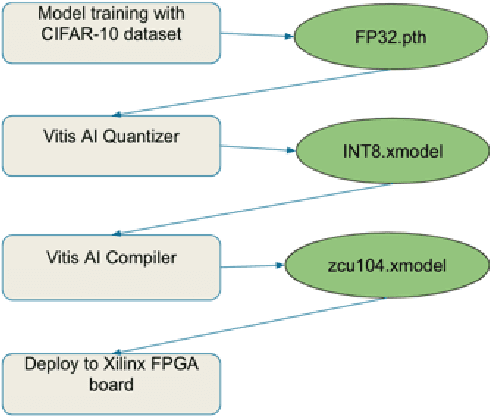


In recent years, Convolutional Neural Networks (CNNs) have been widely adopted in computer vision. Complex CNN architecture running on CPU or GPU has either insufficient throughput or prohibitive power consumption. Hence, there is a need to have dedicated hardware to accelerate the computation workload to solve these limitations. In this paper, we accelerate a CNN for image classification with the CIFAR-10 dataset using Vitis-AI on Xilinx Zynq UltraScale+ MPSoC ZCU104 FPGA evaluation board. The work achieves 3.33-5.82x higher throughput and 3.39-6.30x higher energy efficiency than CPU and GPU baselines. It shows the potential to extract 2D features for downstream tasks, such as depth estimation and 3D reconstruction.
An Overview of Machine Learning-Driven Resource Allocation in IoT Networks
Dec 27, 2024

In the wake of disruptive IoT technologies generating massive amounts of diverse data, Machine Learning (ML) will play a crucial role in bringing intelligence to Internet of Things (IoT) networks. This paper provides a comprehensive analysis of the current state of resource allocation within IoT networks, focusing specifically on two key categories: Low-Power IoT Networks and Mobile IoT Networks. We delve into the resource allocation strategies that are crucial for optimizing network performance and energy efficiency in these environments. Furthermore, the paper explores the transformative role of Machine Learning (ML), Deep Learning (DL), and Reinforcement Learning (RL) in enhancing IoT functionalities. We highlight a range of applications and use cases where these advanced technologies can significantly improve decision-making and optimization processes. In addition to the opportunities presented by ML, DL, and RL, we also address the potential challenges that organizations may face when implementing these technologies in IoT settings. These challenges include crucial accuracy, low flexibility and adaptability, and high computational cost, etc. Finally, the paper identifies promising avenues for future research, emphasizing the need for innovative solutions to overcome existing hurdles and improve the integration of ML, DL, and RL into IoT networks. By providing this holistic perspective, we aim to contribute to the ongoing discourse on resource allocation strategies and the application of intelligent technologies in the IoT landscape.
Generative Adversarial Network on Motion-Blur Image Restoration
Dec 27, 2024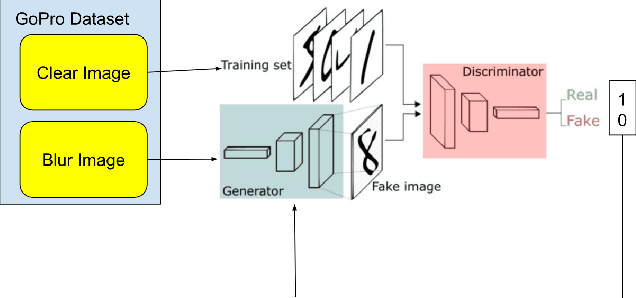



In everyday life, photographs taken with a camera often suffer from motion blur due to hand vibrations or sudden movements. This phenomenon can significantly detract from the quality of the images captured, making it an interesting challenge to develop a deep learning model that utilizes the principles of adversarial networks to restore clarity to these blurred pixels. In this project, we will focus on leveraging Generative Adversarial Networks (GANs) to effectively deblur images affected by motion blur. A GAN-based Tensorflow model is defined, training and evaluating by GoPro dataset which comprises paired street view images featuring both clear and blurred versions. This adversarial training process between Discriminator and Generator helps to produce increasingly realistic images over time. Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM) are the two evaluation metrics used to provide quantitative measures of image quality, allowing us to evaluate the effectiveness of the deblurring process. Mean PSNR in 29.1644 and mean SSIM in 0.7459 with average 4.6921 seconds deblurring time are achieved in this project. The blurry pixels are sharper in the output of GAN model shows a good image restoration effect in real world applications.
Image Deblurring using GAN
Dec 15, 2023



In recent years, deep generative models, such as Generative Adversarial Network (GAN), has grabbed significant attention in the field of computer vision. This project focuses on the application of GAN in image deblurring with the aim of generating clearer images from blurry inputs caused by factors such as motion blur. However, traditional image restoration techniques have limitations in handling complex blurring patterns. Hence, a GAN-based framework is proposed as a solution to generate high-quality deblurred images. The project defines a GAN model in Tensorflow and trains it with GoPRO dataset. The Generator will intake blur images directly to create fake images to convince the Discriminator which will receive clear images at the same time and distinguish between the real image and the fake image. After obtaining the trained parameters, the model was used to deblur motion-blur images taken in daily life as well as testing set for validation. The result shows that the pretrained network of GAN can obtain sharper pixels in image, achieving an average of 29.3 Peak Signal-to-Noise Ratio (PSNR) and 0.72 Structural Similarity Assessment (SSIM). This help to effectively address the challenges posed by image blurring, leading to the generation of visually pleasing and sharp images. By exploiting the adversarial learning framework, the proposed approach enhances the potential for real-world applications in image restoration.