 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimeAttack: Local Explainable Method for Textual Hard-Label Adversarial Attack
Aug 01, 2023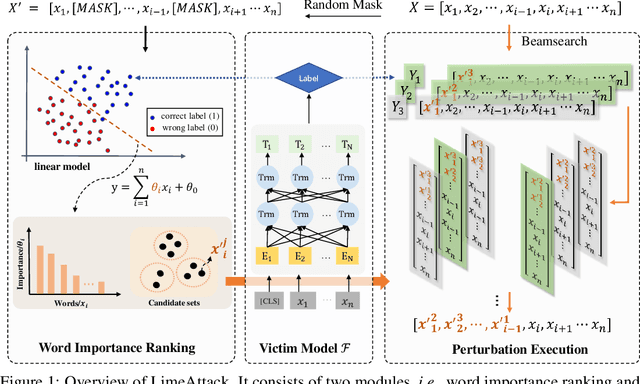
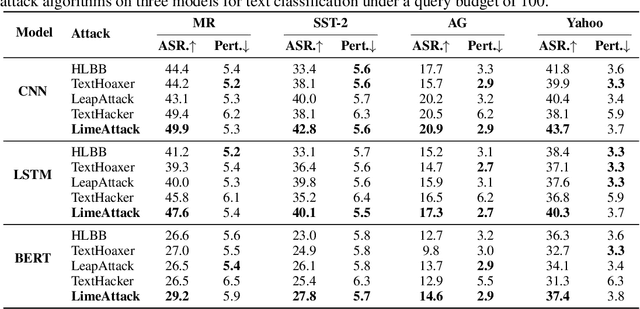
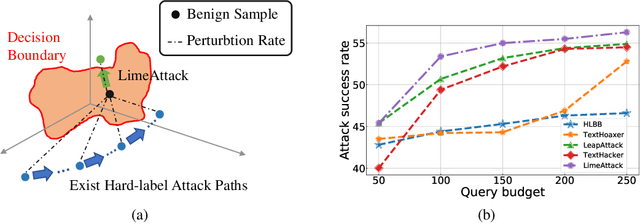
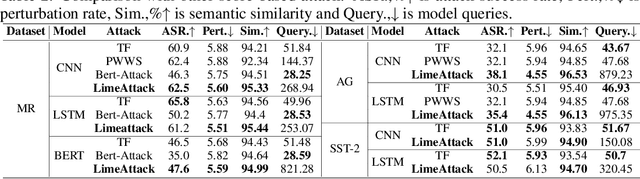
Natural language processing models are vulnerable to adversarial examples. Previous textual adversarial attacks adopt gradients or confidence scores to calculate word importance ranking and generate adversarial examples. However, this information is unavailable in the real world. Therefore, we focus on a more realistic and challenging setting, named hard-label attack, in which the attacker can only query the model and obtain a discrete prediction label. Existing hard-label attack algorithms tend to initialize adversarial examples by random substitution and then utilize complex heuristic algorithms to optimize the adversarial perturbation. These methods require a lot of model queries and the attack success rate is restricted by adversary initialization. In this paper, we propose a novel hard-label attack algorithm named LimeAttack, which leverages a local explainable method to approximate word importance ranking, and then adopts beam search to find the optimal solution. Extensive experiments show that LimeAttack achieves the better attacking performance compared with existing hard-label attack under the same query budget. In addition, we evaluate the effectiveness of LimeAttack on large language models, and results indicate that adversarial examples remain a significant threat to large language models. The adversarial examples crafted by LimeAttack are highly transferable and effectively improve model robustness in adversarial training.