 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Select: Query-Aware Adaptive Dimension Selection for Dense Retrieval
Feb 03, 2026Dense retrieval represents queries and docu-002 ments as high-dimensional embeddings, but003 these representations can be redundant at the004 query level: for a given information need, only005 a subset of dimensions is consistently help-006 ful for ranking. Prior work addresses this via007 pseudo-relevance feedback (PRF) based dimen-008 sion importance estimation, which can produce009 query-aware masks without labeled data but010 often relies on noisy pseudo signals and heuris-011 tic test-time procedures. In contrast, super-012 vised adapter methods leverage relevance labels013 to improve embedding quality, yet they learn014 global transformations shared across queries015 and do not explicitly model query-aware di-016 mension importance. We propose a Query-017 Aware Adaptive Dimension Selection frame-018 work that learns to predict per-dimension im-019 portance directly from query embedding. We020 first construct oracle dimension importance dis-021 tributions over embedding dimensions using022 supervised relevance labels, and then train a023 predictor to map a query embedding to these024 label-distilled importance scores. At inference,025 the predictor selects a query-aware subset of026 dimensions for similarity computation based027 solely on the query embedding, without pseudo-028 relevance feedback. Experiments across multi-029 ple dense retrievers and benchmarks show that030 our learned dimension selector improves re-031 trieval effectiveness over the full-dimensional032 baseline as well as PRF-based masking and033 supervised adapter baselines.
A Text is Worth Several Tokens: Text Embedding from LLMs Secretly Aligns Well with The Key Tokens
Jun 25, 2024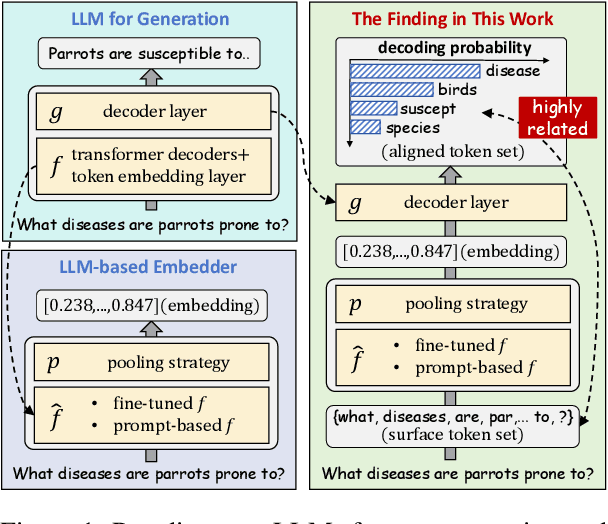
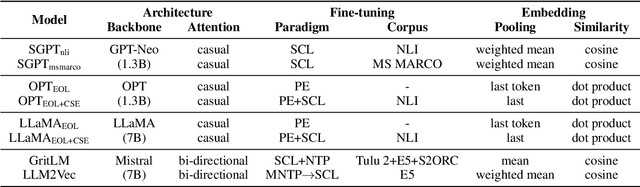

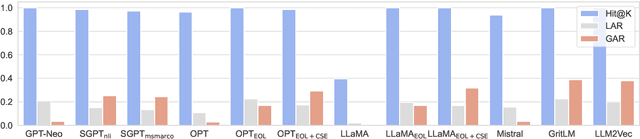
Text embeddings from large language models (LLMs) have achieved excellent results in tasks such as information retrieval, semantic textual similarity, etc. In this work, we show an interesting finding: when feeding a text into the embedding LLMs, the obtained text embedding will be able to be aligned with the key tokens in the input text. We first fully analyze this phenomenon on eight embedding LLMs and show that this phenomenon is universal and is not affected by model architecture, training strategy, and embedding method. With a deeper analysis, we then find that the main change in embedding space between the embedding LLMs and their original generative LLMs is in the first principal component. By adjusting the first principal component, we can align text embedding with the key tokens. Finally, we give several examples to demonstrate the vast application potential of this finding: (1) we propose a simple and practical sparse retrieval method based on the aligned tokens, which can achieve 80\% of the dense retrieval effect of the same model while reducing the computation significantly; (2) we show that our findings provide a fresh perspective to help understand fuzzy concepts (e.g., semantic relatedness vs. semantic similarity) and emerging technologies (e.g., instruction-following embedding) in this field.