 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACP-ESM: A novel framework for classification of anticancer peptides using protein-oriented transformer approach
Jan 04, 2024Anticancer peptides (ACPs) are a class of molecules that have gained significant attention in the field of cancer research and therapy. ACPs are short chains of amino acids, the building blocks of proteins, and they possess the ability to selectively target and kill cancer cells. One of the key advantages of ACPs is their ability to selectively target cancer cells while sparing healthy cells to a greater extent. This selectivity is often attributed to differences in the surface properties of cancer cells compared to normal cells. That is why ACPs are being investigated as potential candidates for cancer therapy. ACPs may be used alone or in combination with other treatment modalities like chemotherapy and radiation therapy. While ACPs hold promise as a novel approach to cancer treatment, there are challenges to overcome, including optimizing their stability, improving selectivity, and enhancing their delivery to cancer cells, continuous increasing in number of peptide sequences, developing a reliable and precise prediction model. In this work, we propose an efficient transformer-based framework to identify anticancer peptides for by performing accurate a reliable and precise prediction model. For this purpose, four different transformer models, namely ESM, ProtBert, BioBERT, and SciBERT are employed to detect anticancer peptides from amino acid sequences. To demonstrate the contribution of the proposed framework, extensive experiments are carried on widely-used datasets in the literature, two versions of AntiCp2, cACP-DeepGram, ACP-740. Experiment results show the usage of proposed model enhances classification accuracy when compared to the state-of-the-art studies. The proposed framework, ESM, exhibits 96.45 of accuracy for AntiCp2 dataset, 97.66 of accuracy for cACP-DeepGram dataset, and 88.51 of accuracy for ACP-740 dataset, thence determining new state-of-the-art.
A novel transformer-based approach for soil temperature prediction
Nov 20, 2023Soil temperature is one of the most significant parameters that plays a crucial role in glacier energy, dynamics of mass balance, processes of surface hydrological, coaction of glacier-atmosphere, nutrient cycling, ecological stability, the management of soil, water, and field crop. In this work, we introduce a novel approach using transformer models for the purpose of forecasting soil temperature prediction. To the best of our knowledge, the usage of transformer models in this work is the very first attempt to predict soil temperature. Experiments are carried out using six different FLUXNET stations by modeling them with five different transformer models, namely, Vanilla Transformer, Informer, Autoformer, Reformer, and ETSformer. To demonstrate the effectiveness of the proposed model, experiment results are compared with both deep learning approaches and literature studies. Experiment results show that the utilization of transformer models ensures a significant contribution to the literature, thence determining the new state-of-the-art.
Heart Disease Detection using Vision-Based Transformer Models from ECG Images
Oct 19, 2023Heart disease, also known as cardiovascular disease, is a prevalent and critical medical condition characterized by the impairment of the heart and blood vessels, leading to various complications such as coronary artery disease, heart failure, and myocardial infarction. The timely and accurate detection of heart disease is of paramount importance in clinical practice. Early identification of individuals at risk enables proactive interventions, preventive measures, and personalized treatment strategies to mitigate the progression of the disease and reduce adverse outcomes. In recent years, the field of heart disease detection has witnessed notable advancements due to the integration of sophisticated technologies and computational approaches. These include machine learning algorithms, data mining techniques, and predictive modeling frameworks that leverage vast amounts of clinical and physiological data to improve diagnostic accuracy and risk stratification. In this work, we propose to detect heart disease from ECG images using cutting-edge technologies, namely vision transformer models. These models are Google-Vit, Microsoft-Beit, and Swin-Tiny. To the best of our knowledge, this is the initial endeavor concentrating on the detection of heart diseases through image-based ECG data by employing cuttingedge technologies namely, transformer models. To demonstrate the contribution of the proposed framework, the performance of vision transformer models are compared with state-of-the-art studies. Experiment results show that the proposed framework exhibits remarkable classification results.
An Efficient Consolidation of Word Embedding and Deep Learning Techniques for Classifying Anticancer Peptides: FastText+BiLSTM
Sep 21, 2023Anticancer peptides (ACPs) are a group of peptides that exhibite antineoplastic properties. The utilization of ACPs in cancer prevention can present a viable substitute for conventional cancer therapeutics, as they possess a higher degree of selectivity and safety. Recent scientific advancements generate an interest in peptide-based therapies which offer the advantage of efficiently treating intended cells without negatively impacting normal cells. However, as the number of peptide sequences continues to increase rapidly, developing a reliable and precise prediction model becomes a challenging task. In this work, our motivation is to advance an efficient model for categorizing anticancer peptides employing the consolidation of word embedding and deep learning models. First, Word2Vec and FastText are evaluated as word embedding techniques for the purpose of extracting peptide sequences. Then, the output of word embedding models are fed into deep learning approaches CNN, LSTM, BiLSTM. To demonstrate the contribution of proposed framework, extensive experiments are carried on widely-used datasets in the literature, ACPs250 and Independent. Experiment results show the usage of proposed model enhances classification accuracy when compared to the state-of-the-art studies. The proposed combination, FastText+BiLSTM, exhibits 92.50% of accuracy for ACPs250 dataset, and 96.15% of accuracy for Independent dataset, thence determining new state-of-the-art.
Evaluating raw waveforms with deep learning frameworks for speech emotion recognition
Jul 06, 2023Speech emotion recognition is a challenging task in speech processing field. For this reason, feature extraction process has a crucial importance to demonstrate and process the speech signals. In this work, we represent a model, which feeds raw audio files directly into the deep neural networks without any feature extraction stage for the recognition of emotions utilizing six different data sets, EMO-DB, RAVDESS, TESS, CREMA, SAVEE, and TESS+RAVDESS. To demonstrate the contribution of proposed model, the performance of traditional feature extraction techniques namely, mel-scale spectogram, mel-frequency cepstral coefficients, are blended with machine learning algorithms, ensemble learning methods, deep and hybrid deep learning techniques. Support vector machine, decision tree, naive Bayes, random forests models are evaluated as machine learning algorithms while majority voting and stacking methods are assessed as ensemble learning techniques. Moreover, convolutional neural networks, long short-term memory networks, and hybrid CNN- LSTM model are evaluated as deep learning techniques and compared with machine learning and ensemble learning methods. To demonstrate the effectiveness of proposed model, the comparison with state-of-the-art studies are carried out. Based on the experiment results, CNN model excels existent approaches with 95.86% of accuracy for TESS+RAVDESS data set using raw audio files, thence determining the new state-of-the-art. The proposed model performs 90.34% of accuracy for EMO-DB with CNN model, 90.42% of accuracy for RAVDESS with CNN model, 99.48% of accuracy for TESS with LSTM model, 69.72% of accuracy for CREMA with CNN model, 85.76% of accuracy for SAVEE with CNN model in speaker-independent audio categorization problems.
An ensemble-based framework for mispronunciation detection of Arabic phonemes
Jan 03, 2023Determination of mispronunciations and ensuring feedback to users are maintained by computer-assisted language learning (CALL) systems. In this work, we introduce an ensemble model that defines the mispronunciation of Arabic phonemes and assists learning of Arabic, effectively. To the best of our knowledge, this is the very first attempt to determine the mispronunciations of Arabic phonemes employing ensemble learning techniques and conventional machine learning models, comprehensively. In order to observe the effect of feature extraction techniques, mel-frequency cepstrum coefficients (MFCC), and Mel spectrogram are blended with each learning algorithm. To show the success of proposed model, 29 letters in the Arabic phonemes, 8 of which are hafiz, are voiced by a total of 11 different person. The amount of data set has been enhanced employing the methods of adding noise, time shifting, time stretching, pitch shifting. Extensive experiment results demonstrate that the utilization of voting classifier as an ensemble algorithm with Mel spectrogram feature extraction technique exhibits remarkable classification result with 95.9% of accuracy.
A Novel Deep Reinforcement Learning Based Stock Direction Prediction using Knowledge Graph and Community Aware Sentiments
Jul 02, 2021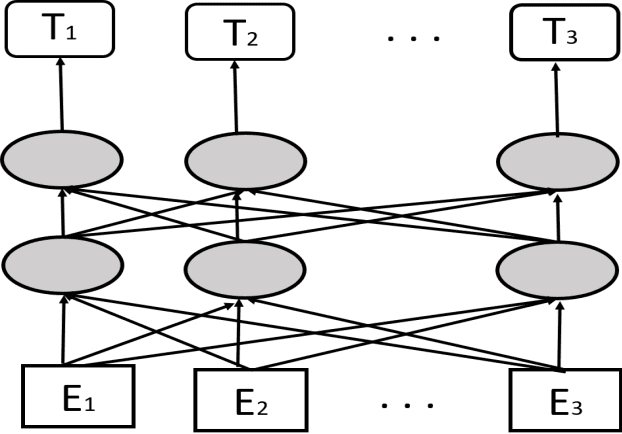


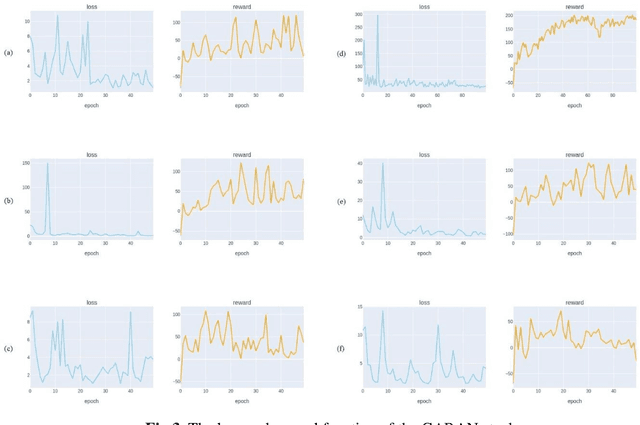
Stock market prediction has been an important topic for investors, researchers, and analysts. Because it is affected by too many factors, stock market prediction is a difficult task to handle. In this study, we propose a novel method that is based on deep reinforcement learning methodologies for the direction prediction of stocks using sentiments of community and knowledge graph. For this purpose, we firstly construct a social knowledge graph of users by analyzing relations between connections. After that, time series analysis of related stock and sentiment analysis is blended with deep reinforcement methodology. Turkish version of Bidirectional Encoder Representations from Transformers (BerTurk) is employed to analyze the sentiments of the users while deep Q-learning methodology is used for the deep reinforcement learning side of the proposed model to construct the deep Q network. In order to demonstrate the effectiveness of the proposed model, Garanti Bank (GARAN), Akbank (AKBNK), T\"urkiye \.I\c{s} Bankas{\i} (ISCTR) stocks in Istanbul Stock Exchange are used as a case study. Experiment results show that the proposed novel model achieves remarkable results for stock market prediction task.