 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotated Runtime Smooth: Training-Free Activation Smoother for accurate INT4 inference
Sep 30, 2024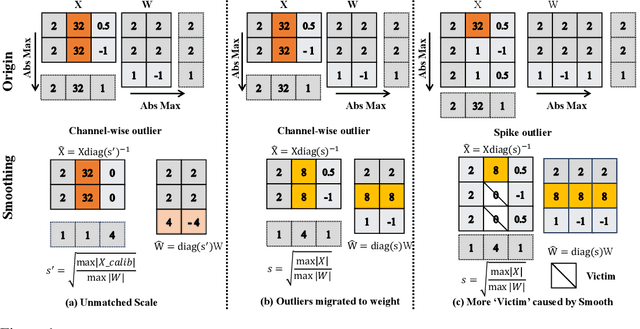
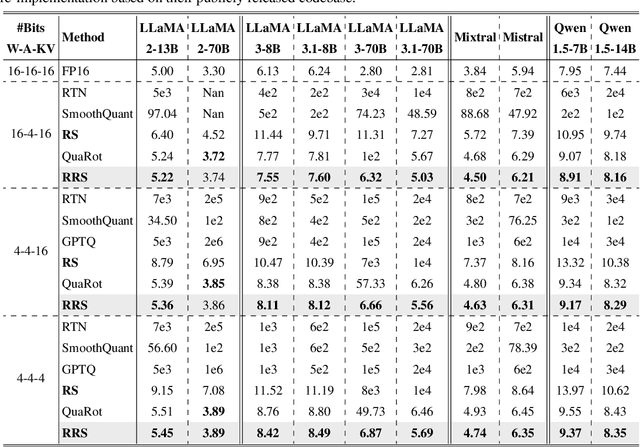
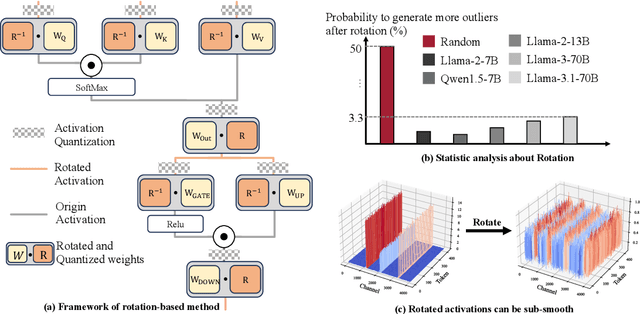
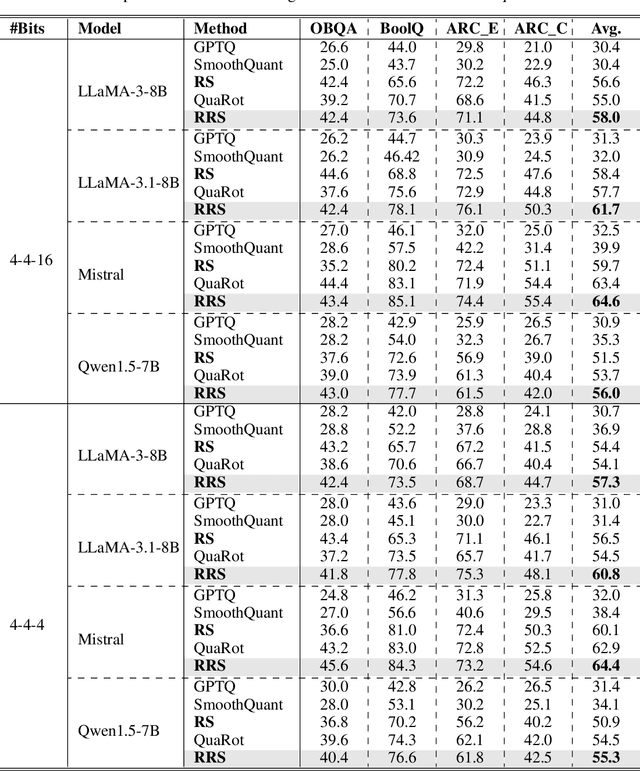
Large language models have demonstrated promising capabilities upon scaling up parameters. However, serving large language models incurs substantial computation and memory movement costs due to their large scale. Quantization methods have been employed to reduce service costs and latency. Nevertheless, outliers in activations hinder the development of INT4 weight-activation quantization. Existing approaches separate outliers and normal values into two matrices or migrate outliers from activations to weights, suffering from high latency or accuracy degradation. Based on observing activations from large language models, outliers can be classified into channel-wise and spike outliers. In this work, we propose Rotated Runtime Smooth (RRS), a plug-and-play activation smoother for quantization, consisting of Runtime Smooth and the Rotation operation. Runtime Smooth (RS) is introduced to eliminate channel-wise outliers by smoothing activations with channel-wise maximums during runtime. The rotation operation can narrow the gap between spike outliers and normal values, alleviating the effect of victims caused by channel-wise smoothing. The proposed method outperforms the state-of-the-art method in the LLaMA and Qwen families and improves WikiText-2 perplexity from 57.33 to 6.66 for INT4 inference.