 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Classifier Design Tuned to Dataset Characteristics for Network Intrusion Detection
May 08, 2022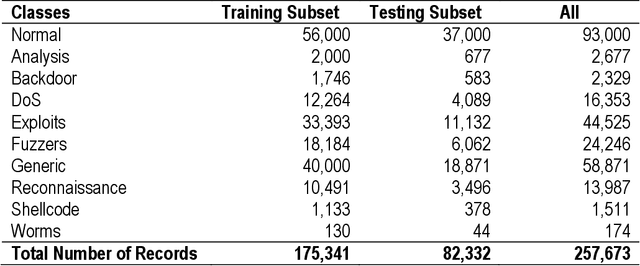
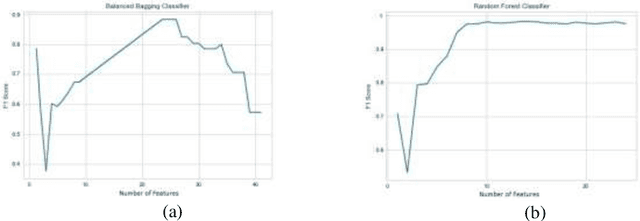
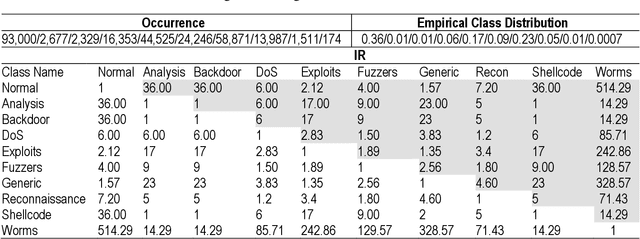

Machine Learning-based supervised approaches require highly customized and fine-tuned methodologies to deliver outstanding performance. This paper presents a dataset-driven design and performance evaluation of a machine learning classifier for the network intrusion dataset UNSW-NB15. Analysis of the dataset suggests that it suffers from class representation imbalance and class overlap in the feature space. We employed ensemble methods using Balanced Bagging (BB), eXtreme Gradient Boosting (XGBoost), and Random Forest empowered by Hellinger Distance Decision Tree (RF-HDDT). BB and XGBoost are tuned to handle the imbalanced data, and Random Forest (RF) classifier is supplemented by the Hellinger metric to address the imbalance issue. Two new algorithms are proposed to address the class overlap issue in the dataset. These two algorithms are leveraged to help improve the performance of the testing dataset by modifying the final classification decision made by three base classifiers as part of the ensemble classifier which employs a majority vote combiner. The proposed design is evaluated for both binary and multi-category classification. Comparing the proposed model to those reported on the same dataset in the literature demonstrate that the proposed model outperforms others by a significant margin for both binary and multi-category classification cases.
Prediction of terephthalic acid (TPA) yield in aqueous hydrolysis of polyethylene terephthalate (PET)
Jan 29, 2022



Aqueous hydrolysis is used to chemically recycle polyethylene terephthalate (PET) due to the production of high-quality terephthalic acid (TPA), the PET monomer. PET hydrolysis depends on various reaction conditions including PET size, catalyst concentration, reaction temperature, etc. So, modeling PET hydrolysis by considering the effective factors can provide useful information for material scientists to specify how to design and run these reactions. It will save time, energy, and materials by optimizing the hydrolysis conditions. Machine learning algorithms enable to design models to predict output results. For the first time, 381 experimental data were gathered to model the aqueous hydrolysis of PET. Effective reaction conditions on PET hydrolysis were connected to TPA yield. The logistic regression was applied to rank the reaction conditions. Two algorithms were proposed, artificial neural network multilayer perceptron (ANN-MLP) and adaptive network-based fuzzy inference system (ANFIS). The dataset was divided into training and testing sets to train and test the models, respectively. The models predicted TPA yield sufficiently where the ANFIS model outperformed. R-squared (R2) and Root Mean Square Error (RMSE) loss functions were employed to measure the efficiency of the models and evaluate their performance.