 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFarSSiBERT: A Novel Transformer-based Model for Semantic Similarity Measurement of Persian Social Networks Informal Texts
Jul 27, 2024One fundamental task for NLP is to determine the similarity between two texts and evaluate the extent of their likeness. The previous methods for the Persian language have low accuracy and are unable to comprehend the structure and meaning of texts effectively. Additionally, these methods primarily focus on formal texts, but in real-world applications of text processing, there is a need for robust methods that can handle colloquial texts. This requires algorithms that consider the structure and significance of words based on context, rather than just the frequency of words. The lack of a proper dataset for this task in the Persian language makes it important to develop such algorithms and construct a dataset for Persian text. This paper introduces a new transformer-based model to measure semantic similarity between Persian informal short texts from social networks. In addition, a Persian dataset named FarSSiM has been constructed for this purpose, using real data from social networks and manually annotated and verified by a linguistic expert team. The proposed model involves training a large language model using the BERT architecture from scratch. This model, called FarSSiBERT, is pre-trained on approximately 104 million Persian informal short texts from social networks, making it one of a kind in the Persian language. Moreover, a novel specialized informal language tokenizer is provided that not only performs tokenization on formal texts well but also accurately identifies tokens that other Persian tokenizers are unable to recognize. It has been demonstrated that our proposed model outperforms ParsBERT, laBSE, and multilingual BERT in the Pearson and Spearman's coefficient criteria. Additionally, the pre-trained large language model has great potential for use in other NLP tasks on colloquial text and as a tokenizer for less-known informal words.
Colloquial Persian POS Corpus: A Novel Corpus for Colloquial Persian Part of Speech Tagging
Oct 01, 2023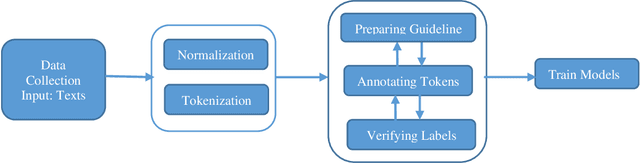

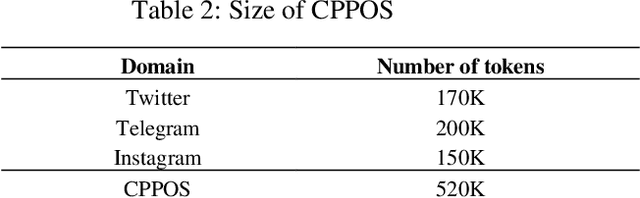
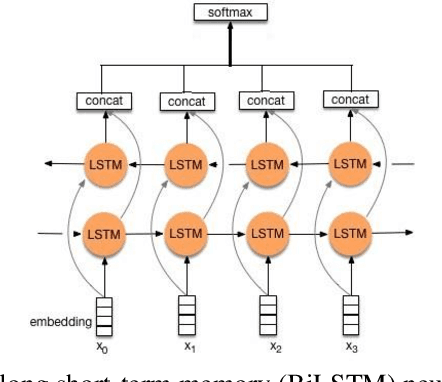
Introduction: Part-of-Speech (POS) Tagging, the process of classifying words into their respective parts of speech (e.g., verb or noun), is essential in various natural language processing applications. POS tagging is a crucial preprocessing task for applications like machine translation, question answering, sentiment analysis, etc. However, existing corpora for POS tagging in Persian mainly consist of formal texts, such as daily news and newspapers. As a result, smart POS tools, machine learning models, and deep learning models trained on these corpora may not perform optimally for processing colloquial text in social network analysis. Method: This paper introduces a novel corpus, "Colloquial Persian POS" (CPPOS), specifically designed to support colloquial Persian text. The corpus includes formal and informal text collected from various domains such as political, social, and commercial on Telegram, Twitter, and Instagram more than 520K labeled tokens. After collecting posts from these social platforms for one year, special preprocessing steps were conducted, including normalization, sentence tokenizing, and word tokenizing for social text. The tokens and sentences were then manually annotated and verified by a team of linguistic experts. This study also defines a POS tagging guideline for annotating the data and conducting the annotation process. Results: To evaluate the quality of CPPOS, various deep learning models, such as the RNN family, were trained using the constructed corpus. A comparison with another well-known Persian POS corpus named "Bijankhan" and the Persian Hazm POS tool trained on Bijankhan revealed that our model trained on CPPOS outperforms them. With the new corpus and the BiLSTM deep neural model, we achieved a 14% improvement over the previous dataset.
Constructing Colloquial Dataset for Persian Sentiment Analysis of Social Microblogs
Jun 22, 2023Introduction: Microblogging websites have massed rich data sources for sentiment analysis and opinion mining. In this regard, sentiment classification has frequently proven inefficient because microblog posts typically lack syntactically consistent terms and representatives since users on these social networks do not like to write lengthy statements. Also, there are some limitations to low-resource languages. The Persian language has exceptional characteristics and demands unique annotated data and models for the sentiment analysis task, which are distinctive from text features within the English dialect. Method: This paper first constructs a user opinion dataset called ITRC-Opinion by collaborative environment and insource way. Our dataset contains 60,000 informal and colloquial Persian texts from social microblogs such as Twitter and Instagram. Second, this study proposes a new deep convolutional neural network (CNN) model for more effective sentiment analysis of colloquial text in social microblog posts. The constructed datasets are used to evaluate the presented model. Furthermore, some models, such as LSTM, CNN-RNN, BiLSTM, and BiGRU with different word embeddings, including Fasttext, Glove, and Word2vec, investigated our dataset and evaluated the results. Results: The results demonstrate the benefit of our dataset and the proposed model (72% accuracy), displaying meaningful improvement in sentiment classification performance.
A Survey on sentiment analysis in Persian: A Comprehensive System Perspective Covering Challenges and Advances in Resources, and Methods
Apr 30, 2021
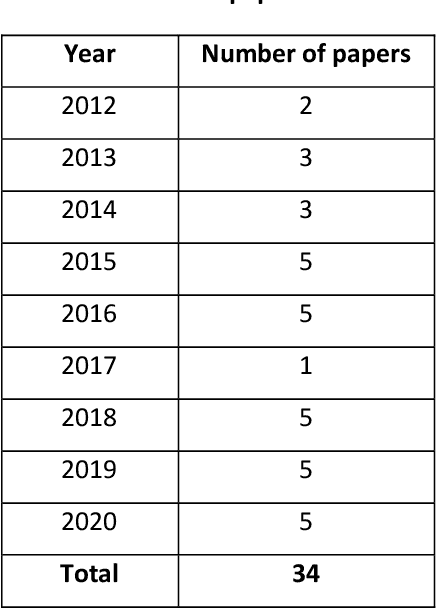
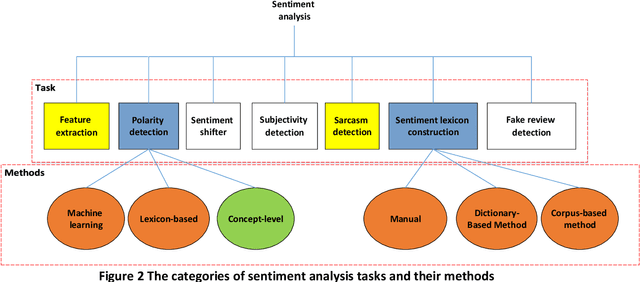
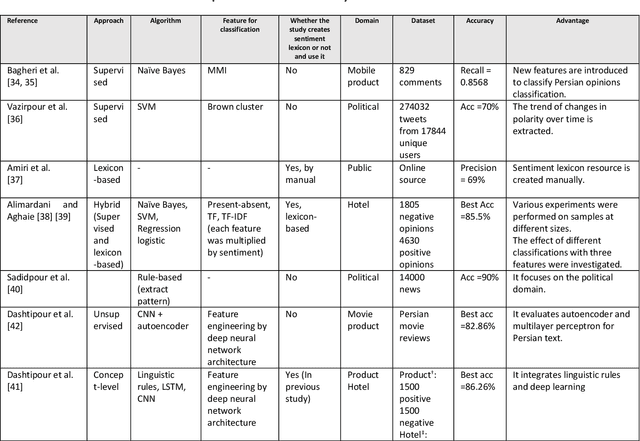
Social media has been remarkably grown during the past few years. Nowadays, posting messages on social media websites has become one of the most popular Internet activities. The vast amount of user-generated content has made social media the most extensive data source of public opinion. Sentiment analysis is one of the techniques used to analyze user-generated data. The Persian language has specific features and thereby requires unique methods and models to be adopted for sentiment analysis, which are different from those in English language. Sentiment analysis in each language has specified prerequisites; hence, the direct use of methods, tools, and resources developed for English language in Persian has its limitations. The main target of this paper is to provide a comprehensive literature survey for state-of-the-art advances in Persian sentiment analysis. In this regard, the present study aims to investigate and compare the previous sentiment analysis studies on Persian texts and describe contributions presented in articles published in the last decade. First, the levels, approaches, and tasks for sentiment analysis are described. Then, a detailed survey of the sentiment analysis methods used for Persian texts is presented, and previous relevant works on Persian Language are discussed. Moreover, we present in this survey the authentic and published standard sentiment analysis resources and advances that have been done for Persian sentiment analysis. Finally, according to the state-of-the-art development of English sentiment analysis, some issues and challenges not being addressed in Persian texts are listed, and some guidelines and trends are provided for future research on Persian texts. The paper provides information to help new or established researchers in the field as well as industry developers who aim to deploy an operational complete sentiment analysis system.
A Context-based Disambiguation Model for Sentiment Concepts Using a Bag-of-concepts Approach
Aug 07, 2020
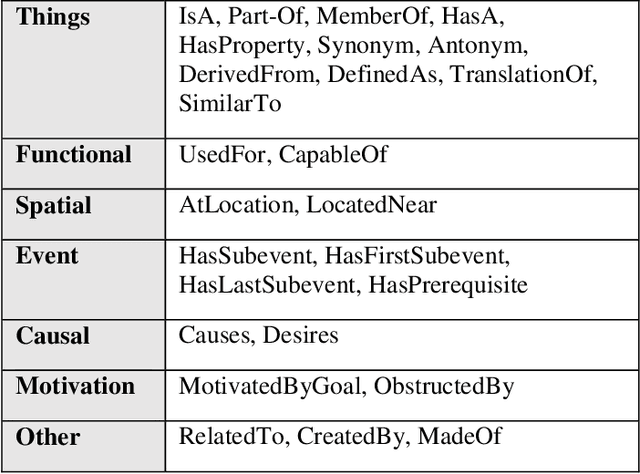
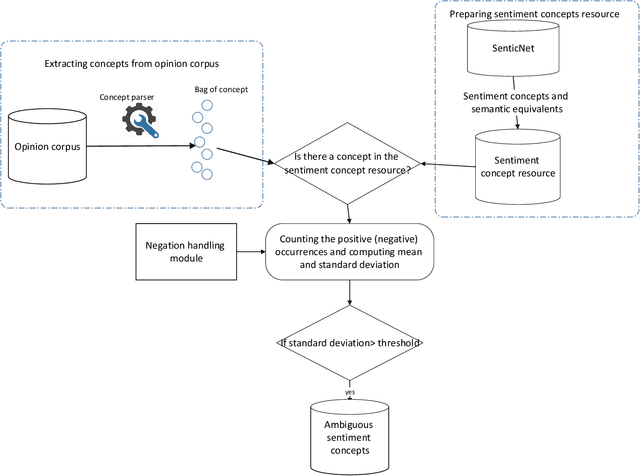
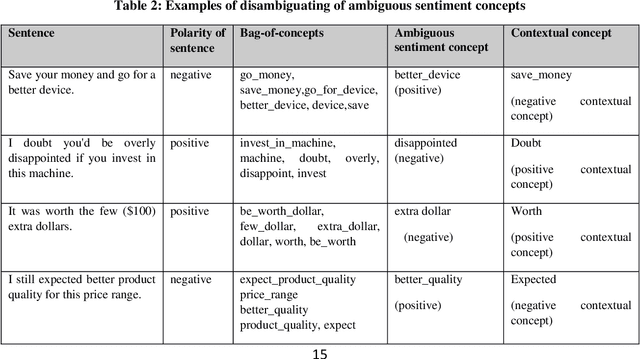
With the widespread dissemination of user-generated content on different social networks, and online consumer systems such as Amazon, the quantity of opinionated information available on the Internet has been increased. One of the main tasks of the sentiment analysis is to detect polarity within a text. The existing polarity detection methods mainly focus on keywords and their naive frequency counts; however, they less regard the meanings and implicit dimensions of the natural concepts. Although background knowledge plays a critical role in determining the polarity of concepts, it has been disregarded in polarity detection methods. This study presents a context-based model to solve ambiguous polarity concepts using commonsense knowledge. First, a model is presented to generate a source of ambiguous sentiment concepts based on SenticNet by computing the probability distribution. Then the model uses a bag-of-concepts approach to remove ambiguities and semantic augmentation with the ConceptNet handling to overcome lost knowledge. ConceptNet is a large-scale semantic network with a large number of commonsense concepts. In this paper, the point mutual information (PMI) measure is used to select the contextual concepts having strong relationships with ambiguous concepts. The polarity of the ambiguous concepts is precisely detected using positive/negative contextual concepts and the relationship of the concepts in the semantic knowledge base. The text representation scheme is semantically enriched using Numberbatch, which is a word embedding model based on the concepts from the ConceptNet semantic network. The proposed model is evaluated by applying a corpus of product reviews, called Semeval. The experimental results revealed an accuracy rate of 82.07%, representing the effectiveness of the proposed model.