 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPR-FCN: Weakly Supervised Visual Relation Detection via Parallel Pairwise R-FCN
Aug 07, 2017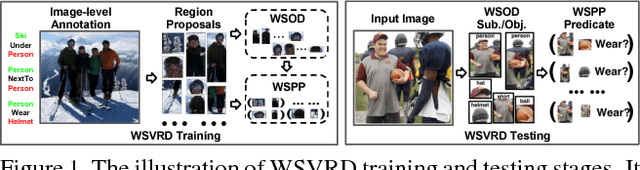
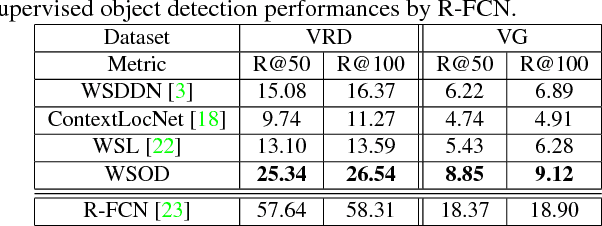
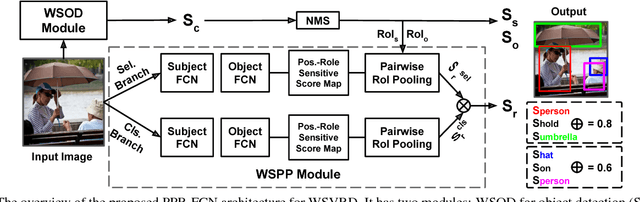
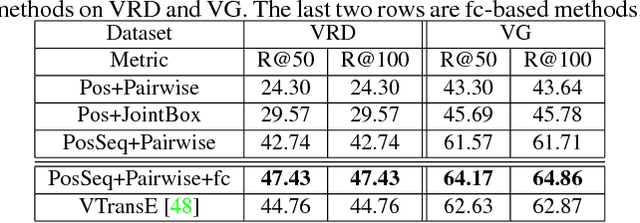
We aim to tackle a novel vision task called Weakly Supervised Visual Relation Detection (WSVRD) to detect "subject-predicate-object" relations in an image with object relation groundtruths available only at the image level. This is motivated by the fact that it is extremely expensive to label the combinatorial relations between objects at the instance level. Compared to the extensively studied problem, Weakly Supervised Object Detection (WSOD), WSVRD is more challenging as it needs to examine a large set of regions pairs, which is computationally prohibitive and more likely stuck in a local optimal solution such as those involving wrong spatial context. To this end, we present a Parallel, Pairwise Region-based, Fully Convolutional Network (PPR-FCN) for WSVRD. It uses a parallel FCN architecture that simultaneously performs pair selection and classification of single regions and region pairs for object and relation detection, while sharing almost all computation shared over the entire image. In particular, we propose a novel position-role-sensitive score map with pairwise RoI pooling to efficiently capture the crucial context associated with a pair of objects. We demonstrate the superiority of PPR-FCN over all baselines in solving the WSVRD challenge by using results of extensive experiments over two visual relation benchmarks.
Visual Translation Embedding Network for Visual Relation Detection
Feb 27, 2017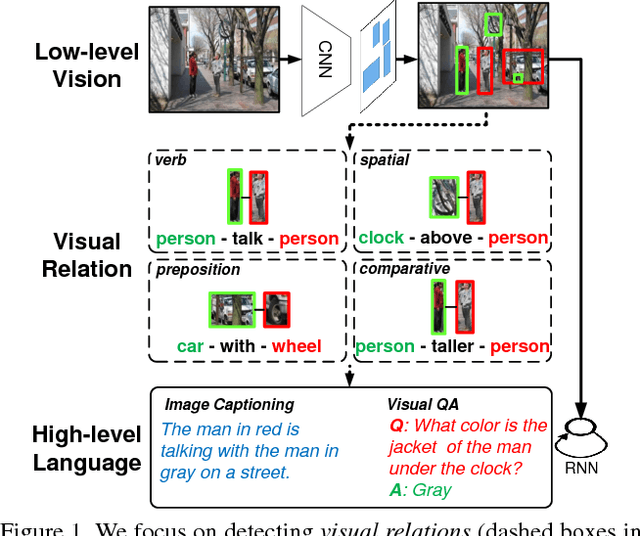



Visual relations, such as "person ride bike" and "bike next to car", offer a comprehensive scene understanding of an image, and have already shown their great utility in connecting computer vision and natural language. However, due to the challenging combinatorial complexity of modeling subject-predicate-object relation triplets, very little work has been done to localize and predict visual relations. Inspired by the recent advances in relational representation learning of knowledge bases and convolutional object detection networks, we propose a Visual Translation Embedding network (VTransE) for visual relation detection. VTransE places objects in a low-dimensional relation space where a relation can be modeled as a simple vector translation, i.e., subject + predicate $\approx$ object. We propose a novel feature extraction layer that enables object-relation knowledge transfer in a fully-convolutional fashion that supports training and inference in a single forward/backward pass. To the best of our knowledge, VTransE is the first end-to-end relation detection network. We demonstrate the effectiveness of VTransE over other state-of-the-art methods on two large-scale datasets: Visual Relationship and Visual Genome. Note that even though VTransE is a purely visual model, it is still competitive to the Lu's multi-modal model with language priors.