 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetClean: Retrieval-Based Data Cleaning Using Foundation Models and Data Lakes
Mar 29, 2023

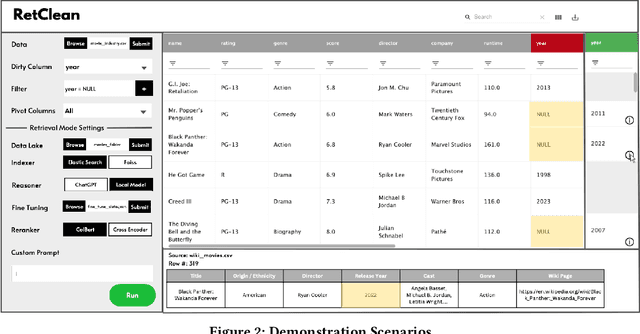
Can foundation models (such as ChatGPT) clean your data? In this proposal, we demonstrate that indeed ChatGPT can assist in data cleaning by suggesting corrections for specific cells in a data table (scenario 1). However, ChatGPT may struggle with datasets it has never encountered before (e.g., local enterprise data) or when the user requires an explanation of the source of the suggested clean values. To address these issues, we developed a retrieval-based method that complements ChatGPT's power with a user-provided data lake. The data lake is first indexed, we then retrieve the top-k relevant tuples to the user's query tuple and finally leverage ChatGPT to infer the correct value (scenario 2). Nevertheless, sharing enterprise data with ChatGPT, an externally hosted model, might not be feasible for privacy reasons. To assist with this scenario, we developed a custom RoBERTa-based foundation model that can be locally deployed. By fine-tuning it on a small number of examples, it can effectively make value inferences based on the retrieved tuples (scenario 3). Our proposed system, RetClean, seamlessly supports all three scenarios and provides a user-friendly GUI that enables the VLDB audience to explore and experiment with the system.