 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFanar 2.0: Arabic Generative AI Stack
Mar 17, 2026We present Fanar 2.0, the second generation of Qatar's Arabic-centric Generative AI platform. Sovereignty is a first-class design principle: every component, from data pipelines to deployment infrastructure, was designed and operated entirely at QCRI, Hamad Bin Khalifa University. Fanar 2.0 is a story of resource-constrained excellence: the effort ran on 256 NVIDIA H100 GPUs, with Arabic having only ~0.5% of web data despite 400 million native speakers. Fanar 2.0 adopts a disciplined strategy of data quality over quantity, targeted continual pre-training, and model merging to achieve substantial gains within these constraints. At the core is Fanar-27B, continually pre-trained from a Gemma-3-27B backbone on a curated corpus of 120 billion high-quality tokens across three data recipes. Despite using 8x fewer pre-training tokens than Fanar 1.0, it delivers substantial benchmark improvements: Arabic knowledge (+9.1 pts), language (+7.3 pts), dialects (+3.5 pts), and English capability (+7.6 pts). Beyond the core LLM, Fanar 2.0 introduces a rich stack of new capabilities. FanarGuard is a state-of-the-art 4B bilingual moderation filter for Arabic safety and cultural alignment. The speech family Aura gains a long-form ASR model for hours-long audio. Oryx vision family adds Arabic-aware image and video understanding alongside culturally grounded image generation. An agentic tool-calling framework enables multi-step workflows. Fanar-Sadiq utilizes a multi-agent architecture for Islamic content. Fanar-Diwan provides classical Arabic poetry generation. FanarShaheen delivers LLM-powered bilingual translation. A redesigned multi-layer orchestrator coordinates all components through intent-aware routing and defense-in-depth safety validation. Taken together, Fanar 2.0 demonstrates that sovereign, resource-constrained AI development can produce systems competitive with those built at far greater scale.
Cross Modal Data Discovery over Structured and Unstructured Data Lakes
Jun 07, 2023Organizations are collecting increasingly large amounts of data for data driven decision making. These data are often dumped into a centralized repository, e.g., a data lake, consisting of thousands of structured and unstructured datasets. Perversely, such mixture of datasets makes the problem of discovering elements (e.g., tables or documents) that are relevant to a user's query or an analytical task very challenging. Despite the recent efforts in data discovery, the problem remains widely open especially in the two fronts of (1) discovering relationships and relatedness across structured and unstructured datasets where existing techniques suffer from either scalability, being customized for a specific problem type (e.g., entity matching or data integration), or demolishing the structural properties on its way, and (2) developing a holistic system for integrating various similarity measurements and sketches in an effective way to boost the discovery accuracy. In this paper, we propose a new data discovery system, named CMDL, for addressing these two limitations. CMDL supports the data discovery process over both structured and unstructured data while retaining the structural properties of tables.
RetClean: Retrieval-Based Data Cleaning Using Foundation Models and Data Lakes
Mar 29, 2023

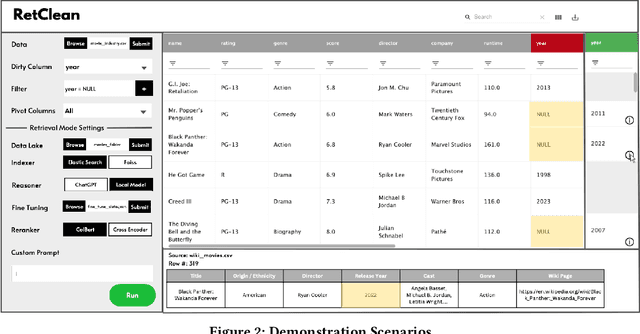
Can foundation models (such as ChatGPT) clean your data? In this proposal, we demonstrate that indeed ChatGPT can assist in data cleaning by suggesting corrections for specific cells in a data table (scenario 1). However, ChatGPT may struggle with datasets it has never encountered before (e.g., local enterprise data) or when the user requires an explanation of the source of the suggested clean values. To address these issues, we developed a retrieval-based method that complements ChatGPT's power with a user-provided data lake. The data lake is first indexed, we then retrieve the top-k relevant tuples to the user's query tuple and finally leverage ChatGPT to infer the correct value (scenario 2). Nevertheless, sharing enterprise data with ChatGPT, an externally hosted model, might not be feasible for privacy reasons. To assist with this scenario, we developed a custom RoBERTa-based foundation model that can be locally deployed. By fine-tuning it on a small number of examples, it can effectively make value inferences based on the retrieved tuples (scenario 3). Our proposed system, RetClean, seamlessly supports all three scenarios and provides a user-friendly GUI that enables the VLDB audience to explore and experiment with the system.