 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproaches to Corpus Creation for Low-Resource Language Technology: the Case of Southern Kurdish and Laki
Apr 03, 2023One of the major challenges that under-represented and endangered language communities face in language technology is the lack or paucity of language data. This is also the case of the Southern varieties of the Kurdish and Laki languages for which very limited resources are available with insubstantial progress in tools. To tackle this, we provide a few approaches that rely on the content of local news websites, a local radio station that broadcasts content in Southern Kurdish and fieldwork for Laki. In this paper, we describe some of the challenges of such under-represented languages, particularly in writing and standardization, and also, in retrieving sources of data and retro-digitizing handwritten content to create a corpus for Southern Kurdish and Laki. In addition, we study the task of language identification in light of the other variants of Kurdish and Zaza-Gorani languages.
Persian Abstract Meaning Representation
May 16, 2022
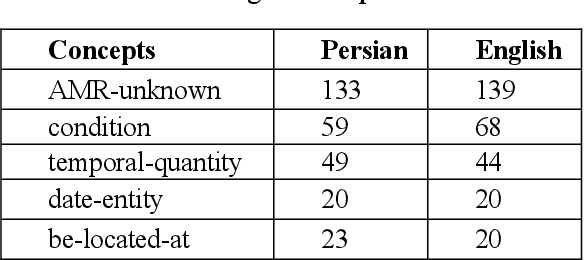

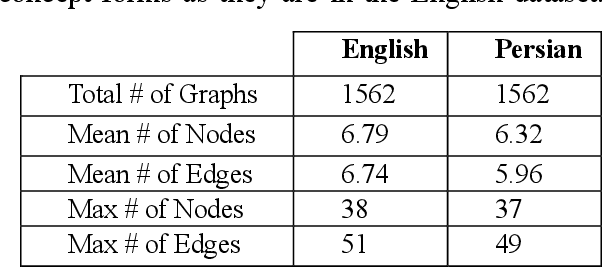
Abstract Meaning Representation (AMR) is an annotation framework representing the semantic structure of a sentence as a whole. From the beginning, AMR was not intended to act as an interlingua; however, it has made progress towards the idea of designing a universal meaning representation framework. Accordingly, developing AMR annotation guidelines for different languages, based on language divergences, is of significant importance. In this paper, we elaborate on Persian Abstract Meaning Representation (PAMR) annotation specifications, based on which we annotated the Persian translation of "The Little Prince" as the first gold standard for Persian AMR. Moreover, we describe how some Persian-specific syntactic constructions would result in different AMR annotations.