 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Models for Simulation of KamLAND-Zen
Dec 22, 2023The next generation of searches for neutrinoless double beta decay (0{\nu}\b{eta}\b{eta}) are poised to answer deep questions on the nature of neutrinos and the source of the Universe's matter-antimatter asymmetry. They will be looking for event rates of less than one event per ton of instrumented isotope per year. To claim discovery, accurate and efficient simulations of detector events that mimic 0{\nu}\b{eta}\b{eta} is critical. Traditional Monte Carlo (MC) simulations can be supplemented by machine-learning-based generative models. In this work, we describe the performance of generative models designed for monolithic liquid scintillator detectors like KamLAND to produce highly accurate simulation data without a predefined physics model. We demonstrate its ability to recover low-level features and perform interpolation. In the future, the results of these generative models can be used to improve event classification and background rejection by providing high-quality abundant generated data.
KamNet: An Integrated Spatiotemporal Deep Neural Network for Rare Event Search in KamLAND-Zen
Mar 08, 2022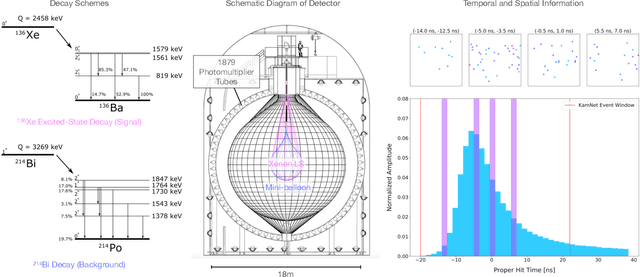
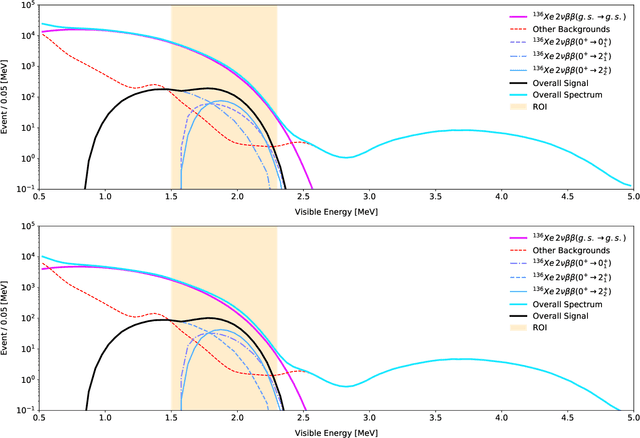
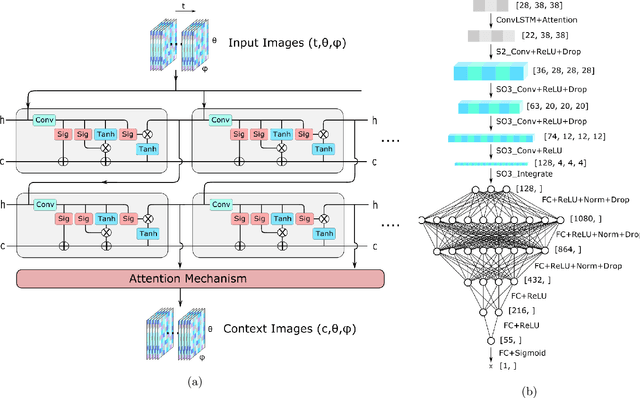
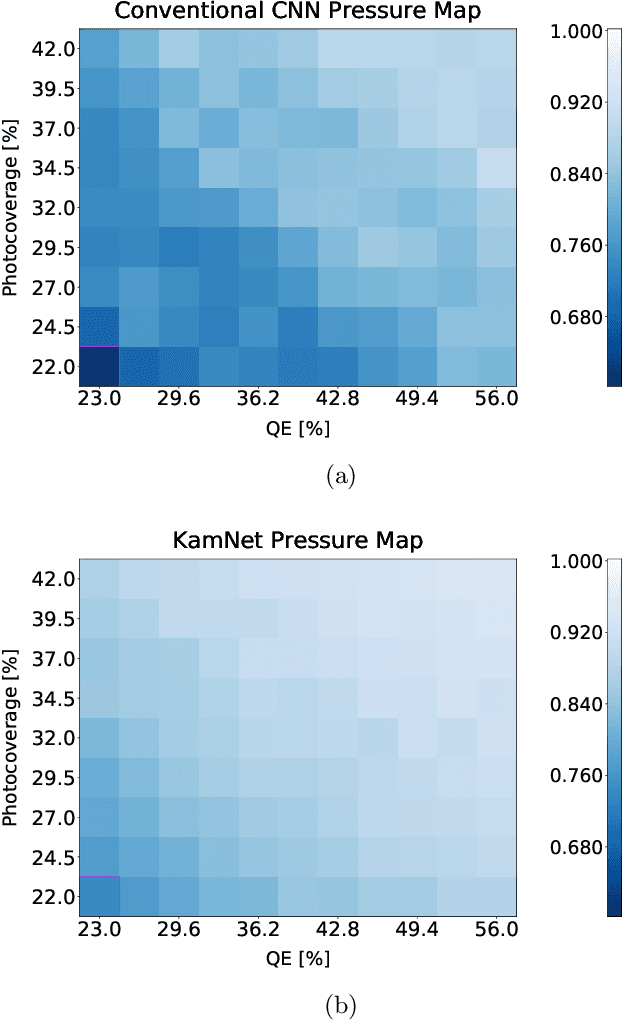
Rare event searches allow us to search for new physics at energy scales inaccessible with other means by leveraging specialized large-mass detectors. Machine learning provides a new tool to maximize the information provided by these detectors. The information is sparse, which forces these algorithms to start from the lowest level data and exploit all symmetries in the detector to produce results. In this work we present KamNet which harnesses breakthroughs in geometric deep learning and spatiotemporal data analysis to maximize the physics reach of KamLAND-Zen, a kiloton scale spherical liquid scintillator detector searching for neutrinoless double beta decay ($0\nu\beta\beta$). Using a simplified background model for KamLAND we show that KamNet outperforms a conventional CNN on benchmarking MC simulations with an increasing level of robustness. Using simulated data, we then demonstrate KamNet's ability to increase KamLAND-Zen's sensitivity to $0\nu\beta\beta$ and $0\nu\beta\beta$ to excited states. A key component of this work is the addition of an attention mechanism to elucidate the underlying physics KamNet is using for the background rejection.
Learnt dynamics generalizes across tasks, datasets, and populations
Dec 04, 2019



Differentiating multivariate dynamic signals is a difficult learning problem as the feature space may be large yet often only a few training examples are available. Traditional approaches to this problem either proceed from handcrafted features or require large datasets to combat the m >> n problem. In this paper, we show that the source of the problem---signal dynamics---can be used to our advantage and noticeably improve classification performance on a range of discrimination tasks when training data is scarce. We demonstrate that self-supervised pre-training guided by signal dynamics produces embedding that generalizes across tasks, datasets, data collection sites, and data distributions. We perform an extensive evaluation of this approach on a range of tasks including simulated data, keyword detection problem, and a range of functional neuroimaging data, where we show that a single embedding learnt on healthy subjects generalizes across a number of disorders, age groups, and datasets.