 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Learning of Region-based pLSA Model for Total Scene Annotation
Nov 21, 2013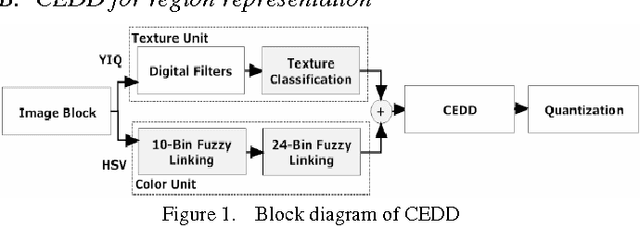
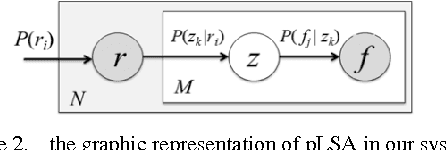
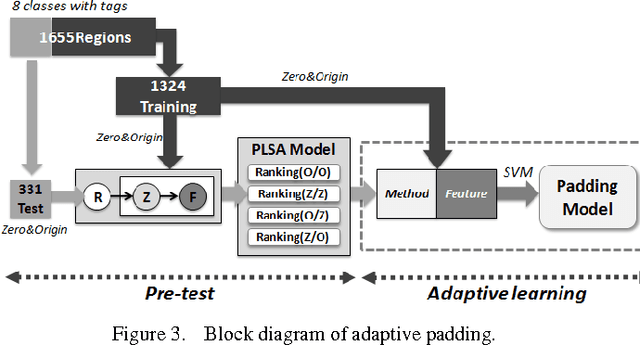

In this paper, we present a region-based pLSA model to accomplish the task of total scene annotation. To be more specific, we not only properly generate a list of tags for each image, but also localizing each region with its corresponding tag. We integrate advantages of different existing region-based works: employ efficient and powerful JSEG algorithm for segmentation so that each region can easily express meaningful object information; the introduction of pLSA model can help better capturing semantic information behind the low-level features. Moreover, we also propose an adaptive padding mechanism to automatically choose the optimal padding strategy for each region, which directly increases the overall system performance. Finally we conduct 3 experiments to verify our ideas on Corel database and demonstrate the effectiveness and accuracy of our system.