 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Perfect Fitting Affect Representation Learning? On the Training Dynamics of Representations in Deep Neural Networks
May 27, 2024

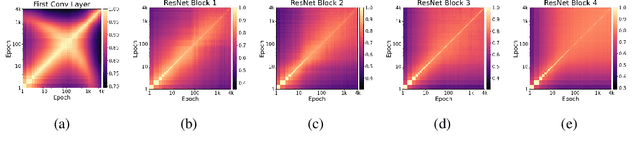
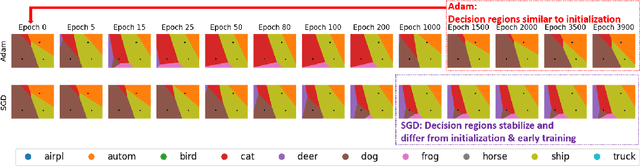
In this paper, we elucidate how representations in deep neural networks (DNNs) evolve during training. We focus on overparameterized learning settings where the training continues much after the trained DNN starts to perfectly fit its training data. We examine the evolution of learned representations along the entire training process, including its perfect fitting regime, and with respect to the epoch-wise double descent phenomenon. We explore the representational similarity of DNN layers, each layer with respect to its own representations throughout the training process. For this, we use two similarity metrics: (1) The centered kernel alignment (CKA) similarity; (2) Similarity of decision regions of linear classifier probes that we train for the DNN layers. Our extensive experiments discover training dynamics patterns that can emerge in layers depending on the relative layer-depth, DNN width, and architecture. We show that representations at the deeper layers evolve much more in the training when an epoch-wise double descent occurs. For Vision Transformer, we show that the perfect fitting threshold creates a transition in the evolution of representations across all the encoder blocks.