 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThermodynamic Limits of Physical Intelligence
Feb 05, 2026Modern AI systems achieve remarkable capabilities at the cost of substantial energy consumption. To connect intelligence to physical efficiency, we propose two complementary bits-per-joule metrics under explicit accounting conventions: (1) Thermodynamic Epiplexity per Joule -- bits of structural information about a theoretical environment-instance variable newly encoded in an agent's internal state per unit measured energy within a stated boundary -- and (2) Empowerment per Joule -- the embodied sensorimotor channel capacity (control information) per expected energetic cost over a fixed horizon. These provide two axes of physical intelligence: recognition (model-building) vs.control (action influence). Drawing on stochastic thermodynamics, we show how a Landauer-scale closed-cycle benchmark for epiplexity acquisition follows as a corollary of a standard thermodynamic-learning inequality under explicit subsystem assumptions, and we clarify how Landauer-scaled costs act as closed-cycle benchmarks under explicit reset/reuse and boundary-closure assumptions; conversely, we give a simple decoupling construction showing that without such assumptions -- and without charging for externally prepared low-entropy resources (e.g.fresh memory) crossing the boundary -- information gain and in-boundary dissipation need not be tightly linked. For empirical settings where the latent structure variable is unavailable, we align the operational notion of epiplexity with compute-bounded MDL epiplexity and recommend reporting MDL-epiplexity / compression-gain surrogates as companions. Finally, we propose a unified efficiency framework that reports both metrics together with a minimal checklist of boundary/energy accounting, coarse-graining/noise, horizon/reset, and cost conventions to reduce ambiguity and support consistent bits-per-joule comparisons, and we sketch connections to energy-adjusted scaling analyses.
Universal AI maximizes Variational Empowerment
Feb 20, 2025This paper presents a theoretical framework unifying AIXI -- a model of universal AI -- with variational empowerment as an intrinsic drive for exploration. We build on the existing framework of Self-AIXI -- a universal learning agent that predicts its own actions -- by showing how one of its established terms can be interpreted as a variational empowerment objective. We further demonstrate that universal AI's planning process can be cast as minimizing expected variational free energy (the core principle of active Inference), thereby revealing how universal AI agents inherently balance goal-directed behavior with uncertainty reduction curiosity). Moreover, we argue that power-seeking tendencies of universal AI agents can be explained not only as an instrumental strategy to secure future reward, but also as a direct consequence of empowerment maximization -- i.e.\ the agent's intrinsic drive to maintain or expand its own controllability in uncertain environments. Our main contribution is to show how these intrinsic motivations (empowerment, curiosity) systematically lead universal AI agents to seek and sustain high-optionality states. We prove that Self-AIXI asymptotically converges to the same performance as AIXI under suitable conditions, and highlight that its power-seeking behavior emerges naturally from both reward maximization and curiosity-driven exploration. Since AIXI can be view as a Bayes-optimal mathematical formulation for Artificial General Intelligence (AGI), our result can be useful for further discussion on AI safety and the controllability of AGI.
Meta Cyclical Annealing Schedule: A Simple Approach to Avoiding Meta-Amortization Error
Mar 04, 2020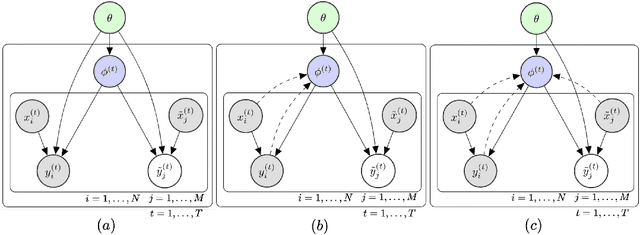



The ability to learn new concepts with small amounts of data is a crucial aspect of intelligence that has proven challenging for deep learning methods. Meta-learning for few-shot learning offers a potential solution to this problem: by learning to learn across data from many previous tasks, few-shot learning algorithms can discover the structure among tasks to enable fast learning of new tasks. However, a critical challenge in few-shot learning is task ambiguity: even when a powerful prior can be meta-learned from a large number of prior tasks, a small dataset for a new task can simply be very ambiguous to acquire a single model for that task. The Bayesian meta-learning models can naturally resolve this problem by putting a sophisticated prior distribution and let the posterior well regularized through Bayesian decision theory. However, currently known Bayesian meta-learning procedures such as VERSA suffer from the so-called {\it information preference problem}, that is, the posterior distribution is degenerated to one point and is far from the exact one. To address this challenge, we design a novel meta-regularization objective using {\it cyclical annealing schedule} and {\it maximum mean discrepancy} (MMD) criterion. The cyclical annealing schedule is quite effective at avoiding such degenerate solutions. This procedure includes a difficult KL-divergence estimation, but we resolve the issue by employing MMD instead of KL-divergence. The experimental results show that our approach substantially outperforms standard meta-learning algorithms.