 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeITACLIP: Boosting Training-Free Semantic Segmentation with Image, Text, and Architectural Enhancements
Nov 18, 2024



Recent advances in foundational Vision Language Models (VLMs) have reshaped the evaluation paradigm in computer vision tasks. These foundational models, especially CLIP, have accelerated research in open-vocabulary computer vision tasks, including Open-Vocabulary Semantic Segmentation (OVSS). Although the initial results are promising, the dense prediction capabilities of VLMs still require further improvement. In this study, we enhance the semantic segmentation performance of CLIP by introducing new modules and modifications: 1) architectural changes in the last layer of ViT and the incorporation of attention maps from the middle layers with the last layer, 2) Image Engineering: applying data augmentations to enrich input image representations, and 3) using Large Language Models (LLMs) to generate definitions and synonyms for each class name to leverage CLIP's open-vocabulary capabilities. Our training-free method, ITACLIP, outperforms current state-of-the-art approaches on segmentation benchmarks such as COCO-Stuff, COCO-Object, Pascal Context, and Pascal VOC. Our code is available at https://github.com/m-arda-aydn/ITACLIP.
PCLD: Point Cloud Layerwise Diffusion for Adversarial Purification
Mar 11, 2024Point clouds are extensively employed in a variety of real-world applications such as robotics, autonomous driving and augmented reality. Despite the recent success of point cloud neural networks, especially for safety-critical tasks, it is essential to also ensure the robustness of the model. A typical way to assess a model's robustness is through adversarial attacks, where test-time examples are generated based on gradients to deceive the model. While many different defense mechanisms are studied in 2D, studies on 3D point clouds have been relatively limited in the academic field. Inspired from PointDP, which denoises the network inputs by diffusion, we propose Point Cloud Layerwise Diffusion (PCLD), a layerwise diffusion based 3D point cloud defense strategy. Unlike PointDP, we propagated the diffusion denoising after each layer to incrementally enhance the results. We apply our defense method to different types of commonly used point cloud models and adversarial attacks to evaluate its robustness. Our experiments demonstrate that the proposed defense method achieved results that are comparable to or surpass those of existing methodologies, establishing robustness through a novel technique. Code is available at https://github.com/batuceng/diffusion-layer-robustness-pc.
epsilon-Mesh Attack: A Surface-based Adversarial Point Cloud Attack for Facial Expression Recognition
Mar 11, 2024Point clouds and meshes are widely used 3D data structures for many computer vision applications. While the meshes represent the surfaces of an object, point cloud represents sampled points from the surface which is also the output of modern sensors such as LiDAR and RGB-D cameras. Due to the wide application area of point clouds and the recent advancements in deep neural networks, studies focusing on robust classification of the 3D point cloud data emerged. To evaluate the robustness of deep classifier networks, a common method is to use adversarial attacks where the gradient direction is followed to change the input slightly. The previous studies on adversarial attacks are generally evaluated on point clouds of daily objects. However, considering 3D faces, these adversarial attacks tend to affect the person's facial structure more than the desired amount and cause malformation. Specifically for facial expressions, even a small adversarial attack can have a significant effect on the face structure. In this paper, we suggest an adversarial attack called $\epsilon$-Mesh Attack, which operates on point cloud data via limiting perturbations to be on the mesh surface. We also parameterize our attack by $\epsilon$ to scale the perturbation mesh. Our surface-based attack has tighter perturbation bounds compared to $L_2$ and $L_\infty$ norm bounded attacks that operate on unit-ball. Even though our method has additional constraints, our experiments on CoMA, Bosphorus and FaceWarehouse datasets show that $\epsilon$-Mesh Attack (Perpendicular) successfully confuses trained DGCNN and PointNet models $99.72\%$ and $97.06\%$ of the time, with indistinguishable facial deformations. The code is available at https://github.com/batuceng/e-mesh-attack.
Symmetry and Variance: Generative Parametric Modelling of Historical Brick Wall Patterns
Oct 23, 2022



This study integrates artificial intelligence and computational design tools to extract information from architectural heritage. Photogrammetry-based point cloud models of brick walls from the Anatolian Seljuk period are analysed in terms of the interrelated units of construction, simultaneously considering both the inherent symmetries and irregularities. The real-world data is used as input for acquiring the stochastic parameters of spatial relations and a set of parametric shape rules to recreate designs of existing and hypothetical brick walls within the style. The motivation is to be able to generate large data sets for machine learning of the style and to devise procedures for robotic production of such designs with repetitive units.
* 10 pages, 7 Figures. This paper is published at "Symmetry: Art and Science | 12th SIS-Symmetry Congress"
Uncertainty-Based Dynamic Graph Neighborhoods For Medical Segmentation
Aug 06, 2021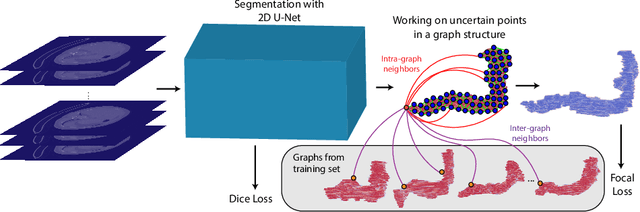
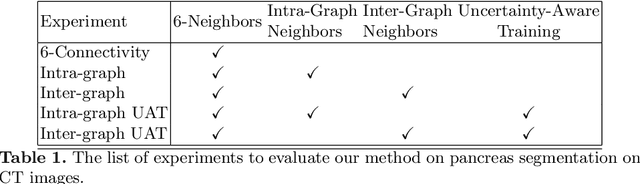
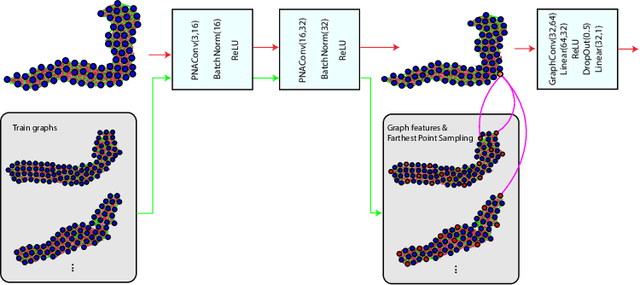

In recent years, deep learning based methods have shown success in essential medical image analysis tasks such as segmentation. Post-processing and refining the results of segmentation is a common practice to decrease the misclassifications originating from the segmentation network. In addition to widely used methods like Conditional Random Fields (CRFs) which focus on the structure of the segmented volume/area, a graph-based recent approach makes use of certain and uncertain points in a graph and refines the segmentation according to a small graph convolutional network (GCN). However, there are two drawbacks of the approach: most of the edges in the graph are assigned randomly and the GCN is trained independently from the segmentation network. To address these issues, we define a new neighbor-selection mechanism according to feature distances and combine the two networks in the training procedure. According to the experimental results on pancreas segmentation from Computed Tomography (CT) images, we demonstrate improvement in the quantitative measures. Also, examining the dynamic neighbors created by our method, edges between semantically similar image parts are observed. The proposed method also shows qualitative enhancements in the segmentation maps, as demonstrated in the visual results.
ODFNet: Using orientation distribution functions to characterize 3D point clouds
Dec 08, 2020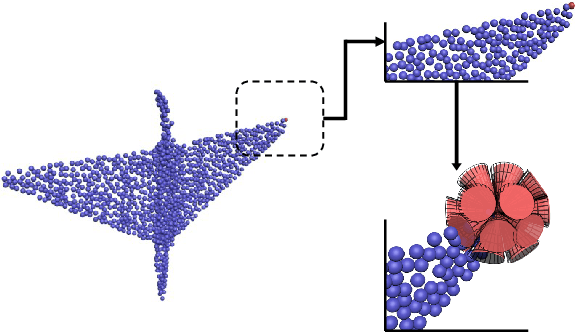
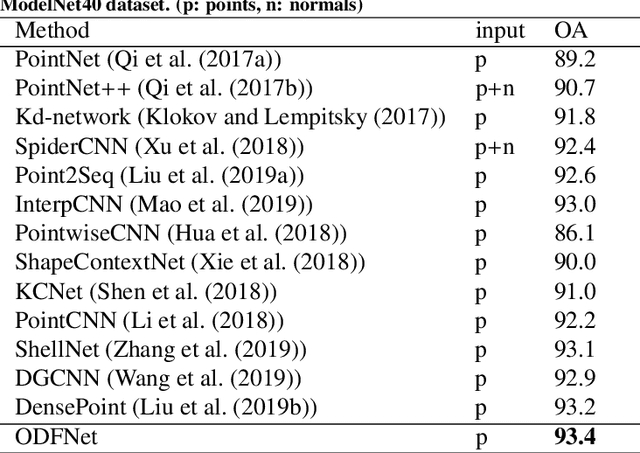

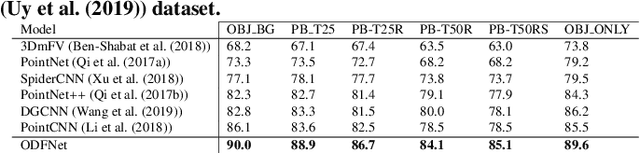
Learning new representations of 3D point clouds is an active research area in 3D vision, as the order-invariant point cloud structure still presents challenges to the design of neural network architectures. Recent works explored learning either global or local features or both for point clouds, however none of the earlier methods focused on capturing contextual shape information by analysing local orientation distribution of points. In this paper, we leverage on point orientation distributions around a point in order to obtain an expressive local neighborhood representation for point clouds. We achieve this by dividing the spherical neighborhood of a given point into predefined cone volumes, and statistics inside each volume are used as point features. In this way, a local patch can be represented by not only the selected point's nearest neighbors, but also considering a point density distribution defined along multiple orientations around the point. We are then able to construct an orientation distribution function (ODF) neural network that involves an ODFBlock which relies on mlp (multi-layer perceptron) layers. The new ODFNet model achieves state-of the-art accuracy for object classification on ModelNet40 and ScanObjectNN datasets, and segmentation on ShapeNet S3DIS datasets.
EfficientSeg: An Efficient Semantic Segmentation Network
Oct 09, 2020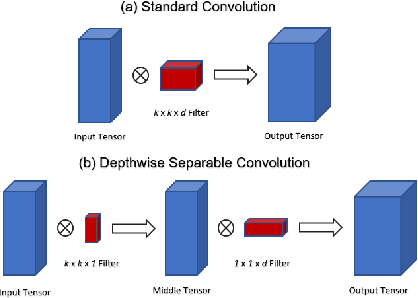

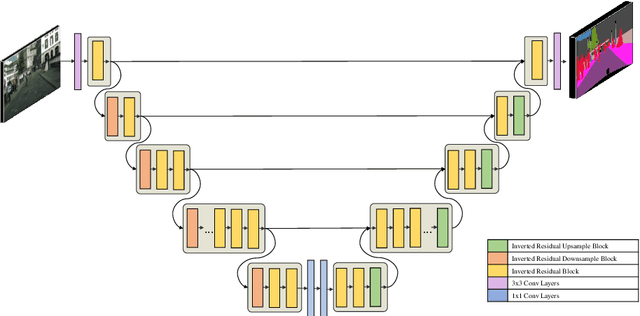
Deep neural network training without pre-trained weights and few data is shown to need more training iterations. It is also known that, deeper models are more successful than their shallow counterparts for semantic segmentation task. Thus, we introduce EfficientSeg architecture, a modified and scalable version of U-Net, which can be efficiently trained despite its depth. We evaluated EfficientSeg architecture on Minicity dataset and outperformed U-Net baseline score (40% mIoU) using the same parameter count (51.5% mIoU). Our most successful model obtained 58.1% mIoU score and got the fourth place in semantic segmentation track of ECCV 2020 VIPriors challenge.