 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond saliency: understanding convolutional neural networks from saliency prediction on layer-wise relevance propagation
Sep 15, 2018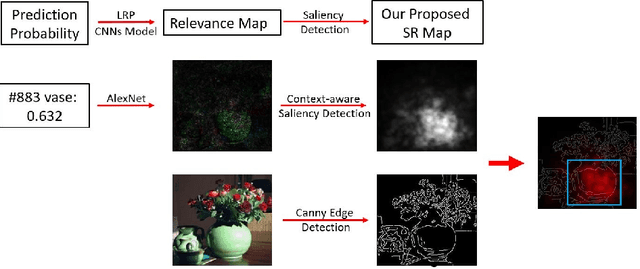
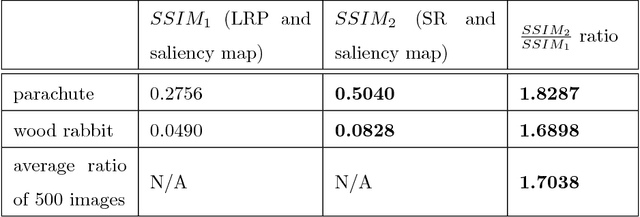

Despite the tremendous achievements of deep convolutional neural networks (CNNs) in many computer vision tasks, understanding how they actually work remains a significant challenge. In this paper, we propose a novel two-step understanding method, namely Salient Relevance (SR) map, which aims to shed light on how deep CNNs recognize images and learn features from areas, referred to as attention areas, therein. Our proposed method starts out with a layer-wise relevance propagation (LRP) step which estimates a pixel-wise relevance map over the input image. Following, we construct a context-aware saliency map, SR map, from the LRP-generated map which predicts areas close to the foci of attention instead of isolated pixels that LRP reveals. In human visual system, information of regions is more important than of pixels in recognition. Consequently, our proposed approach closely simulates human recognition. Experimental results using the ILSVRC2012 validation dataset in conjunction with two well-established deep CNN models, AlexNet and VGG-16, clearly demonstrate that our proposed approach concisely identifies not only key pixels but also attention areas that contribute to the underlying neural network's comprehension of the given images. As such, our proposed SR map constitutes a convenient visual interface which unveils the visual attention of the network and reveals which type of objects the model has learned to recognize after training. The source code is available at https://github.com/Hey1Li/Salient-Relevance-Propagation.